

[SW개발]검색결과, 46건
- 배열 인덱싱의 메커니즘(arr[i] == *(arr+i)) 2023.10.27
- 배열과 포인터(Pointer) 의 상관관계 2023.10.27
- 리터럴(Literal) 상수 2023.10.27
- ASCII 2023.10.27
- 비트(bit) 단위 연산 2023.10.27
- 실수 연산, 어떻게 하시나요??? 2023.09.27
- +- m * n의 e승 2023.09.27
- 실수 데이터의 표현 방식 - 부동소수점 방식 2023.09.27
- 0.1 을 100 번 더해도 10이 되지 않는다? 2023.09.27
- 정수 데이터의 표현 방식 2023.09.27
- 2진수 <-> 8 진수, 16 진수 변환 2023.09.27
- n 진수? 진수 변환 ! 2023.09.27
- 개인정보의 암호화 대상 및 방법 2020.07.28
- The Scale Cube (규모 확장성 모델) 2019.02.21
- 해킹 피해에 따른 행정처분 사례 2019.02.08
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2008년 5월에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=105
『 배열 인덱싱의 메커니즘 』
배열은 다수개의 요소를 가진다.
특정 요소에 접근하기 위해서는 Sequence 한 인덱싱을 사용한다.
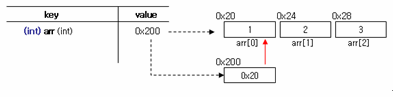
예를 들어, int arr[] = {1,2,3} 으로 정의된 배열의 요소에 접근하기 위해서 arr[0] , arr[1], arr[2] 로 접근할 수 있다.
앞서 우리는 배열 변수는 결국 배열의 첫 번째 요소를 포인팅 하고 있는 포인터라고 배웠다.
이전 그림을 다시 보자.
이전 아티클 보기 -> 배열과 포인터의 상관관계
그렇다면 arr[2] 와 같은 인덱싱은 어떤 처리과정을 통해 3번째 메모리 값을 가져올 수 있는 것일까?
가장 먼저 알아야 할 중요한 내용이 있다.
“배열은 연속된 메모리 공간에 순차적으로 저장된다”
위의 예에서 제시된 int 형 배열 arr 은 0x20 번지부터 4byte 씩 증가하는 연속된 메모리 공간에 값이 저장되는
것이다
즉, 아래 그림과 같이 저장된다.
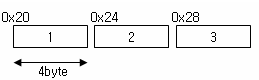
그 다음으로 알아야 할 중요한 내용이다.
“배열은 포인터이다. 배열을 인덱싱은 포인터 연산으로 이루어 진다.”
일단, 배열을 알아보기 이전에 포인터 연산 중 포인터의 주소를 이동 시키는 예제를 살펴 보자.
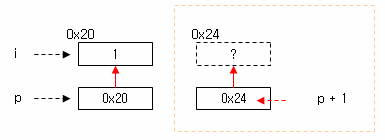
| void main(void){ int i = 1; int *p = &i; printf("%d<=포인터의주소값\n",*&p); p = p + 1; //포인트의주소를한칸이동한다(4byte 만큼메모리이동) printf("%d<=포인트주소이동후주소값\n",*&p); } |
포인터 변수 p 에 1을 더한다.
이 의미는 주소 값인 p 에 1을 더한다는 의미로,
메모리 주소를 한 블럭 증가시키게 된다. 이때 p는 int 형이기 때문에 1 증가는 4byte 단위(블럭)의 증가를 의미한
포인터가 가지는 값은 자신이 포인팅 하고 있는 대상 메모리의 주소 값을 가지고 있다.
따라서 이 포인터의 값을 변경한다는 것은 대상 메모리 주소를 변경한다는 것과 같은 의미이다.
주의해야 할 것은 포인터 값을 증가 시킬 경우에는 포인터의 타입에 따라 자동으로 크기만큼 곱해 진다는 것
을 알아야 한다
이 경우 p 는 int 형 포인터이기 때문에 p + 1 = p + 1 * 4 가 된다. 즉 내부적으로 4(byte) 가 곱해 지는 것이다.
당연하겠지만 4byte 길이 int 형 메모리 공간을 한 칸 이동 한다는 것은 4byte 만큼 이동한다는 것이기 때문이다.
(만일 자동으로 곱해지는 데이터 길이가 헷갈린다면 간편한 이해를 위해서는 그냥 메모리 한 칸 이동한다고 생각하자)
자. 이제 위의 샘플을 실행한 결과를 보자.

포인터의 값이 4 만큼 증가된 것을 보여준다
결론적으로 포인터가 포인팅하는 주소 값이 변경된 것이다.
p 의 변경 전,변경 후 의 실제 포인팅 대상의 값을 보자.

포인팅 주소를 변경하기 전에는 int i =1 이었던 놈을 여전히 포인팅 하고 있고 변경 후에는 이상한 값이 나왔다.
이제 배열로 말해 보자.
다시 말하지만, 배열은 포인터 이며 위와 같은 포인터 연산으로 배열 각 요소를 인덱싱 하는 것이 가능하다
int arr[] = {1,2,3} 라고 정의된 배열이 있으며 이의 메모리 구조는 아래와 같다고 했다.
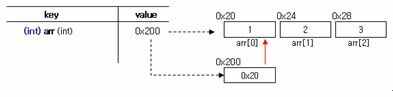
배열 변수인 arr 은 배열의 첫 번째 요소를 포인팅 하는 (상수) 포인터이다.
arr[1] 를 풀이해 보면,
arr 의 값을 1 증가시키고 그 값이 포인팅 하는 대상 메모리의 값을 가져온다.
1. arr 값 1 증가 (int 형 배열일 경우)
arr + 1 = arr + 1 * (4byte)
사실 * 4byte는 생략해도 무방하다
arr 타입에 따라 메모리 블럭 증가는 해당 타입의 메모리 블럭만큼 되는 것은 당연하기 때문이다
2. arr 의 포인팅 하고 있는 대상 메모리 값 참조
*(arr + 1)
결국 arr[1] = *(arr + 1) 이다.
( *(p + 1) 의 식은 p[1] 과 동일하다)
위의 예에서는 arr 을 한 칸 이동하면 0x24가 되고 이 메모리 주소의 값은 2가 되는 것이다.
지금까지의 내용을 그림으로 담아 보았다.
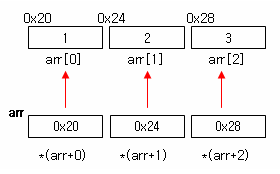
너무 장황하게 설명했지만, 배열의 인덱싱 메커니즘을 한마디로 한 마디로 요약하자면 다음과 같이 할 수 있겠다
“연속된 메모리 공간을 포인터 연산으로 찾아가는 일련의 과정”
배열과 포인터에 관한 중요한 아래의 연산식을 기억하자
arr[i] == *(arr+i)
'SW개발' 카테고리의 다른 글
| 이런... 계집 녀(女) (0) | 2023.10.31 |
|---|---|
| 다차원 배열의 인덱싱 (0) | 2023.10.27 |
| 배열과 포인터(Pointer) 의 상관관계 (0) | 2023.10.27 |
| 리터럴(Literal) 상수 (0) | 2023.10.27 |
| ASCII (0) | 2023.10.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2008년 5월일에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=104
『 배열과 포인터(Pointer) 의 상관관계 』
배열은 포인터이다
대부분의 프로그래밍 언어에서는 배열이라는 복합 값을 다룰 수 있는 자료구조를 제공한다.
배열과 포인터는 내부적인 처리 방식이 거의 동일하다. 단 배열변수는 ‘상수 포인터’ 이다
일단 포인터의 내부 구조를 살펴 보자.
아래 샘플 코드는 int 형 변수를 가리키는 포인터를 생성해서 포인터를 통해서 i 의 값을 변경하는 예제이다.
| void main(void){ int i = 1; int *p = &i; *p = 2; printf("%d",i); } |
시스템은 내부적으로 변수를 메모리에 저장하고 참조하기 위한 key-value 와 유사한 형태의 Symbol Table 라는 것을 관리한다. 이 Symbol Table 에는 변수명과 값이 저장된 메모리 주소 그리고 타입정보를 저장한다.
이것은 포인터도 마찬가지이다.
단, Symbol Table 에서 포인터는 자신의 타입정보 뿐만 아니라 포인팅하고 있는 대상의 타입정보도 같이 저장한다.
편의상 Symbol Table 가 다음과 같이 구성된다고 가정하자.

위의 예제를 Symbol Table 과 메모리 구조로 표현하면 다음과 같다.
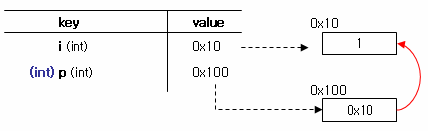
int 형 변수 i 에 1을 저장했으므로 4byte 메모리 공간에 1을 저장하고 그 주소 값인 0x10 번지를 가리킨다.
그리고 i 의 주소 값을 포인팅 하는 포인터 변수 p 는 역시나 4byte 메모리 공간에 i 의 주소값인 0x10 을 저장하고
있는 0x100 번지를 가리킨다
즉 포인터 변수가 가리키는 메로리 공간에는 i 의 메모리 주소가 저장되어 있는 것이다(32 bit 시스템에서 메모리 주소 값은 4byte 로 표현되므로 포인터 p 는 4byte 의 메모리 공간을 차지하게
되는 것이다)
자.. 그럼 이제 배열을 알아 보자. 다음과 같이 선언된 배열이 있다고 가정하자.
| int arr[] = {1,2,3}; |
이 배열을 Symbol Table 과 메모리 구조로 표현하면 다음과 같다.
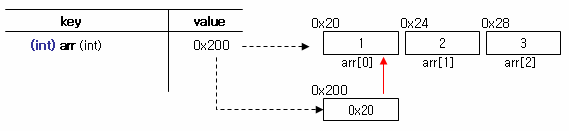
배열 변수인 arr 은 배열의 첫 번째 요소(arr[0]) 를 포인팅 하는 별도의 상수형 메모리 공간인 것이다.
즉 arr 은 0x200 을 가리키고 여기에는 배열의 첫 번째 요소(arr[0]) 의 메모리 주소를 포인팅
하고 있는 것이다. 이 구조는 포인터와 완전히 동일한 구조이다.
실제로 이 배열을 정수형 포인터에 대입하면 포인터를 배열처럼 사용할 수 있다.
| void main(void){ int arr[] = {1,2,3}; int *p = arr; printf("%d,%d,%d",p[0],p[1],p[2]); //1,2,3 이 출력된다 } |
단, int *p = arr 은 가능하지만 arr = p 는 성립하지 않는다.
앞서 말했듯이 arr은 상수이기 때문이다. 상수를 변경할 수는 없는 것이다.
또 하나, 일반적인 포인터에서 *p = 10 하면 p 가 포인팅 하고 있는 곳이 변경된다.
그렇다면 위의 배열 변수를 가지고 *arr = 10 하면 어떻게 되겠는가?
arr 은 배열의 첫 번째 요소를 포인팅하는 포인터이기 때문에 위의 식은 배열의 첫 번째 요소의 값을 변경하게 된다.
| void main(void){ int arr[] = {1,2,3}; *arr = 10; printf("%d,%d,%d",arr[0],arr[1],arr[2]); //10,2,3 이 출력된다 } |
이로써 배열은 포인터 이다 라는 명제를 풀어 보았다.
'SW개발' 카테고리의 다른 글
| 다차원 배열의 인덱싱 (0) | 2023.10.27 |
|---|---|
| 배열 인덱싱의 메커니즘(arr[i] == *(arr+i)) (0) | 2023.10.27 |
| 리터럴(Literal) 상수 (0) | 2023.10.27 |
| ASCII (0) | 2023.10.27 |
| 비트(bit) 단위 연산 (0) | 2023.10.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2008년 5월에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=103
상수란 변수와는 달리 값을 변경할 수 없는 데이터를 의미한다.
즉 아래와 같은 코드에서
int i = 10
i : 정수형 변수
10 : 상수
라고 한다.
i 의 현재 값은 10으로 할당되었지만 프로그램 수행 과정중에 다른 정수값으로 변경이 가능하므로 i 를 (정수형) 변수라 한다.
반면, 10 은 값을 변경할 수 없기 때문에 상수인 것이다.
그렇다면 위의 코드의 실행 순서를 살펴보자.
대입연산자의 실행 우선순위는 우측의 결과가 먼저 실행되고 좌측으로 값이 복사된다(이 과정을 값이 변수로 assign 된다고 한다)
즉 10 이라는 것이 먼저 실행되고 i 에 10이 복사된다는 것이다.
그럼 우측이 실행된다는 의미는 무엇일까?
연산자의 우측에는 10이라는 숫자가 있을 뿐이다.
이 말은 10 이 먼저 메모리에 올라간다는 뜻이다.
컴퓨터의 CPU 는 메모리에 존재하는 데이터들만 연산할 수 있다.
(우리가 작성하는 응용프로그램 역시 실행시에는 메모리에 로드 된다는 것을 알고 있다)
따라서 10 이라는 숫자가 내부적으로 먼저 메모리에 로드되고 난 후 i 라는 변수에 복사가 되는 것이다.
이렇게 특정 메모리에 10 이라는 정수값이 할당이 되었지만 이 메모리 공간의 이름은 부여되지 않았다.
즉, 메모리할당이 되어 상수가 저장되었으나 그 공간에 이름이 없는 상수를 리터럴(literal) 상수라고 한다.

그림에서 보면 위의 10이라는 메모리 공간은 i 라고 이름이 부여되었다. 그러나 아래쪽의 메모리 공간은 10이라는
값을 저장하고는 있지만 이 공간에 대한 이름은 부여되지 않았다. 단지 숫자 10 이 메모리에 저장된것 뿐이다.
이렇듯 이름이 없는 상수를 가리켜 리터럴(literal) 상수라 한다.
이와 반대로 이름이 부여된 상수는 심볼릭(Symbolic) 상수라 한다.
아래의 코드를 보자
const int i = 10;
const 라는 키워드를 사용하여 상수를 정의하고 있다.
이것은 상수이지만 이름이 있으므로 심볼릭(Symbolic) 상수라 한다.
'SW개발' 카테고리의 다른 글
| 배열 인덱싱의 메커니즘(arr[i] == *(arr+i)) (0) | 2023.10.27 |
|---|---|
| 배열과 포인터(Pointer) 의 상관관계 (0) | 2023.10.27 |
| ASCII (0) | 2023.10.27 |
| 비트(bit) 단위 연산 (0) | 2023.10.27 |
| 실수 연산, 어떻게 하시나요??? (0) | 2023.09.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2008년 5월에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=102
ASCII 정의
미국 정보 교환 표준 부호(American Standard Code for Information Interchange) 의 약자인 ASCII 는 영문 알파벳을 사용하는 대표적인 문자 인코딩(Encoding) 이다.
컴퓨터는 0과 1 로 구성된 진수밖에 인식하지 못한다.
이 말은 곧 컴퓨터는 숫자밖에 인식하지 못한다는 의미인 것이다.
그렇다면 컴퓨터에게 문자를 인식하도록 할려면???
그렇다. 숫자밖에 인식하지 못하는 컴퓨터에게 인간의 언어인 문자를 인식하도록 하려면 여전히 숫자를 사용할 수 밖에 없다.
그렇다면 숫자를 이용해서 문자를 표현하는 규칙이 있어야 한다.
즉 숫자 N 은 문자 X 와 일디일 매핑(mapping) 시키는 개념을 규칙화 시켜야 한다.
이러한 매핑 규칙을 정의해 놓은 것이 바로 ASCII 코드표 이다.
아래와 같은 코드를 보자
char c = ‘A’
내부적으로 c 에는 65 라는 정수가 저장된다.
ASCII 구성
총 128 개 (7비트로 표현 가능한 범위 , 2의 7승 = 128) 로 구성

33 개 : 출력 불가능한 제어 문자들
95 개 : 출력 가능한 문자(공백 포함)
52개 : 영문 알파벳 대소문자, 10개의 숫자, 32개의 특수문자, 1개의 공백문자
| 구분 | 개수 | 구간 | |||
| 출력 불가능 제어 문자 |
33 | 0 ~ 31 127 |
|||
| 출력 가능 문자(공백포함) |
95 | 32 ~ 126 | 구분 | 개수 | 구간 |
| 영문 | 52 | 65 ~ 90 (대문자) 97 ~ 122 (소문자) |
|||
| 특수문자 | 32 | 33 ~ 47 58 ~ 64 91 ~ 96 123 ~ 126 |
|||
| 숫자 | 10 | 48 ~ 57 | |||
| 공백문자 | 1 | 32 | |||
출력 가능한 95개 문자 (32 번 ~ 126 번)

ASCII 코드표
| DEC | HEX | OCT | Char | DEC | HEX | OCT | Char | DEC | HEX | OCT | Char | ||
| 0 | 00 | 000 | Ctrl-@ NUL | 43 | 2B | 053 | + | 86 | 56 | 126 | V | ||
| 1 | 01 | 001 | Ctrl-A SOH | 44 | 2C | 054 | , | 87 | 57 | 127 | W | ||
| 2 | 02 | 002 | Ctrl-B STX | 45 | 2D | 055 | - | 88 | 58 | 130 | X | ||
| 3 | 03 | 003 | Ctrl-C ETX | 46 | 2E | 056 | . | 89 | 59 | 131 | Y | ||
| 4 | 04 | 004 | Ctrl-D EOT | 47 | 2F | 057 | / | 90 | 5A | 132 | Z | ||
| 5 | 05 | 005 | Ctrl-E ENQ | 48 | 30 | 060 | 0 | 91 | 5B | 133 | [ | ||
| 6 | 06 | 006 | Ctrl-F ACK | 49 | 31 | 061 | 1 | 92 | 5C | 134 | \ | ||
| 7 | 07 | 007 | Ctrl-G BEL | 50 | 32 | 062 | 2 | 93 | 5D | 135 | ] | ||
| 8 | 08 | 010 | Ctrl-H BS | 51 | 33 | 063 | 3 | 94 | 5E | 136 | ^ | ||
| 9 | 09 | 011 | Ctrl-I HT | 52 | 34 | 064 | 4 | 95 | 5F | 137 | _ | ||
| 10 | 0A | 012 | Ctrl-J LF | 53 | 35 | 065 | 5 | 96 | 60 | 140 | ` | ||
| 11 | 0B | 013 | Ctrl-K VT | 54 | 36 | 066 | 6 | 97 | 61 | 141 | a | ||
| 12 | 0C | 014 | Ctrl-L FF | 55 | 37 | 067 | 7 | 98 | 62 | 142 | b | ||
| 13 | 0D | 015 | Ctrl-M CR | 56 | 38 | 070 | 8 | 99 | 63 | 143 | c | ||
| 14 | 0E | 016 | Ctrl-N SO | 57 | 39 | 071 | 9 | 100 | 64 | 144 | d | ||
| 15 | 0F | 017 | Ctrl-O SI | 58 | 3A | 072 | : | 101 | 65 | 145 | e | ||
| 16 | 10 | 020 | Ctrl-P DLE | 59 | 3B | 073 | ; | 102 | 66 | 146 | f | ||
| 17 | 11 | 021 | Ctrl-Q DCI | 60 | 3C | 074 | < | 103 | 67 | 147 | g | ||
| 18 | 12 | 022 | Ctrl-R DC2 | 61 | 3D | 075 | = | 104 | 68 | 150 | h | ||
| 19 | 13 | 023 | Ctrl-S DC3 | 62 | 3E | 076 | > | 105 | 69 | 151 | i | ||
| 20 | 14 | 024 | Ctrl-T DC4 | 63 | 3F | 077 | ? | 106 | 6A | 152 | j | ||
| 21 | 15 | 025 | Ctrl-U NAK | 64 | 40 | 100 | @ | 107 | 6B | 153 | k | ||
| 22 | 16 | 026 | Ctrl-V SYN | 65 | 41 | 101 | A | 108 | 6C | 154 | l | ||
| 23 | 17 | 027 | Ctrl-W ETB | 66 | 42 | 102 | B | 109 | 6D | 155 | m | ||
| 24 | 18 | 030 | Ctrl-X CAN | 67 | 43 | 103 | C | 110 | 6E | 156 | n | ||
| 25 | 19 | 031 | Ctrl-Y EM | 68 | 44 | 104 | D | 111 | 6F | 157 | o | ||
| 26 | 1A | 032 | Ctrl-Z SUB | 69 | 45 | 105 | E | 112 | 70 | 160 | p | ||
| 27 | 1B | 033 | Ctrl-[ ESC | 70 | 46 | 106 | F | 113 | 71 | 161 | q | ||
| 28 | 1C | 034 | Ctrl-\ FS | 71 | 47 | 107 | G | 114 | 72 | 162 | r | ||
| 29 | 1D | 035 | Ctrl-] GS | 72 | 48 | 110 | H | 115 | 73 | 163 | s | ||
| 30 | 1E | 036 | Ctrl-^ RS | 73 | 49 | 111 | I | 116 | 74 | 164 | t | ||
| 31 | 1F | 037 | Ctrl_ US | 74 | 4A | 112 | J | 117 | 75 | 165 | u | ||
| 32 | 20 | 040 | Space | 75 | 4B | 113 | K | 118 | 76 | 166 | v | ||
| 33 | 21 | 041 | ! | 76 | 4C | 114 | L | 119 | 77 | 167 | w | ||
| 34 | 22 | 042 | " | 77 | 4D | 115 | M | 120 | 78 | 170 | x | ||
| 35 | 23 | 043 | # | 78 | 4E | 116 | N | 121 | 79 | 171 | y | ||
| 36 | 24 | 044 | $ | 79 | 4F | 117 | O | 122 | 7A | 172 | z | ||
| 37 | 25 | 045 | % | 80 | 50 | 120 | P | 123 | 7B | 173 | { | ||
| 38 | 26 | 046 | & | 81 | 51 | 121 | Q | 124 | 7C | 174 | | | ||
| 39 | 27 | 047 | ' | 82 | 52 | 122 | R | 125 | 7D | 175 | } | ||
| 40 | 28 | 050 | ( | 83 | 53 | 123 | S | 126 | 7E | 176 | ~ | ||
| 41 | 29 | 051 | ) | 84 | 54 | 124 | T | 127 | 7F | 177 | DEL | ||
| 42 | 2A | 052 | * | 85 | 55 | 125 | U | ||||||
인쇄 불 가능한 제어 문자
33개에 해당하는 인쇄 불가능 아스키 문자는 프린터와 같은 일부 제어 주변장치를 제어하는데 사용되는 제어 문자이다.
| 10진수 | 문자 | 10진수 | 문자 | |
| 0 | NUL(null) | 16 | DLE(data link escape) | |
| 1 | SOH(start of heading) | 17 | DC1(device control 1) | |
| 2 | SOX(start of text) | 18 | DC2(device control 2) | |
| 3 | EOX(end of text) | 19 | DC3(device control 3) | |
| 4 | EOT(end of transmission) | 20 | DC4(device control 4) | |
| 5 | ENQ(inquiry) | 21 | NAK(negative acknowledge) | |
| 6 | ACK(acknowledge) | 22 | SYN(synchronous idle) | |
| 7 | BEL(bell) | 23 | ETB(end of transmission block) | |
| 8 | BS(backspace) | 24 | CAN(cancel) | |
| 9 | HT(horizontal tab) | 25 | EM(end of medium) | |
| 10 | LF(NL line feed/new line) | 26 | SUB(substitute) | |
| 11 | VT(vertical tab) | 27 | ESC(escape) | |
| 12 | FF(form feed/new page) | 28 | FS(file separator) | |
| 13 | CR(carriage return) | 29 | GS(group separator) | |
| 14 | SO(shift out) | 30 | RS(record separator) | |
| 10 | SI(shift in) | 31 | US(unit separator) |
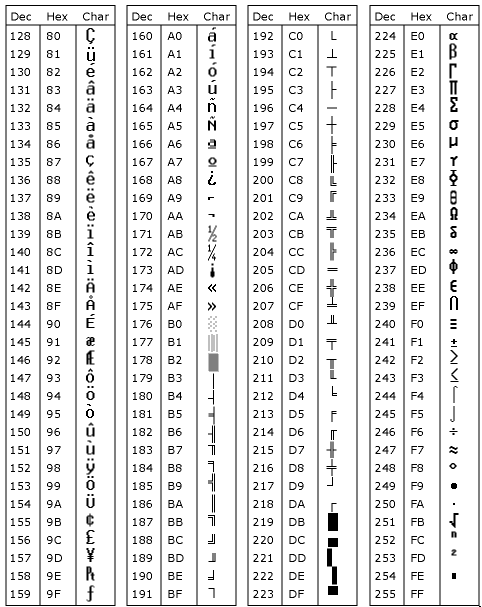
확장 ASCII 인쇄 문자
위의 7 Bit 로는 128개의 문자만을 표현할 수 있다.
더 많은 문자의 표현을 위해 확장 ASCII 라는 것이 있는데 이것은 비트(bit) 를 하나 더 늘려 총 8 Bit 로 표현하게 되어 총 259 개를 표현할 수 있다.
즉 128 ~ 255 까지 문자를 추가적으로 표현할 수 있다
(확장 문자 집합은 ASCII 문자 집합과 128개의 그래픽과 선 그리기용 문자를 포함하며 종종 "IBM 문자 집합"이라고도 합니다)
'SW개발' 카테고리의 다른 글
| 배열과 포인터(Pointer) 의 상관관계 (0) | 2023.10.27 |
|---|---|
| 리터럴(Literal) 상수 (0) | 2023.10.27 |
| 비트(bit) 단위 연산 (0) | 2023.10.27 |
| 실수 연산, 어떻게 하시나요??? (0) | 2023.09.27 |
| +- m * n의 e승 (0) | 2023.09.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2008년 5월에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=101
정보의 최소 단위는 비트(bit)입니다.
보통 프로그램을 작성할때 int,long 등 바이트(byte) 단위롤 연산하도록 프로그램을 작성합니다.
그러나 비트 단위로 연산을 하게 되면 메모리 공간을 줄이고 성능을 향상 시킬 수 있습니다.
주로 하드웨어 프로그래밍에서 자주 사용되는 연산이라 할 수 있습니다.
그러나 의지만 있으면 우리가 작성하는 일반적인(?) 프로그램도 비트 단위 연산을 하면 성능에 아주 좋은 영향을
줍니다. 지금부터 비트 단위로 연산을 하는 방법을 알아 봅니다.
비트 단위 연산에는 아래와 같은 연산자가 있습니다.
& : 비트 단위 AND
| : 비트 단위 OR
^ : 비트 단위 XOR
~ : 비트 단위 NOT
<< : 왼쪽으로 이동
>> : 오른쪽으로 이동
주의 할 점은 비트 단위 연산에서의 피 연산자, 즉 연산의 대상은 반드시 정수이어야 합니다.
실수의 비트 연산은 불가능 합니다.
& (비트 단위 AND) 연산자
두 비트의 값이 모두 1일때 1을 반환합니다.
0 & 0 = 0
0 & 1 = 0
1 & 0 = 0
1 & 1 = 1
ex> 15 & 20 연산은 아래와 같이 수행 됩니다.
00001111
& 00010100
-----------------
00000100 = 4 가 됩니다.
| (비트 단위 OR) 연산자
두 비트 중 하나만 1이면 1을 반환합니다.
0 | 0 = 0
0 | 1 = 1
1 | 0 = 1
1 | 1 = 1
ex> 15 | 20 연산은 아래와 같이 수행 됩니다.
00001111
| 00010100
-----------------
00011111 = 31 가 됩니다.
^ (비트 단위 XOR) 연산자
두 비트가 서로 다를 경우 1을 반환 합니다.
0 ^ 0 = 0
0 ^ 1 = 1
1 ^ 0 = 1
1 ^ 1 = 0
ex> 15 ^ 20 연산은 아래와 같이 수행 됩니다.
00001111
^ 00010100
-----------------
00011011 = 27가 됩니다.
~ (비트 단위 NOT) 연산자
비트를 반전 시킵니다(비트 값의 보수)
~ 0 = 1
~ 1 = 0
ex > ~15 연산은 아래와 같이 수행 됩니다.
NOT 00000000 00000000 00000000 00001111
-------------------------------------------------------------------
11111111 11111111 11111111 11110000 가 됩니다.
부호 비트 까지 반전이 되었으므로 음의 정수 값이 됩니다. (15의 1의 보수가 됩니다)
그리고 1을 더하면(결국 15의 2의 보수) -15가 됩니다
<< 왼쪽 쉬프트 (비트 단위 이동) 연산자
a << b => a의 비트들을 b만큼 왼쪽으로 이동합니다.
ex> 15 << 2 연산은 아래와 같이 수행 됩니다.
00000000 00000000 00000000 00001111 을 왼쪽으로 2칸씩 이동 시킵니다.
00000000 00000000 00000000 00001111 데이터 범위를 넘어서 이동한 비트들은 버려집니다(빨간색 부분)
00000000 00000000 00000000 00111100 이동한 만큼 비어 있는 오른쪽 비트는 0으로 채우게 됩니다(빨간색 부분)
따라서 결과는 60 이 됩니다.
주의 할 점은 맨 앞의 부호 비트 까지 이동하므로 데이터의 부호가 바뀔수 있습니다(양/음이 바뀐다)
>> 오른쪽 쉬프트 (비트 단위 이동) 연산자
a << b => a의 비트들을 b만큼 오른쪽으로 이동합니다.
ex>
위의 식에서 a가 양수이면(부호 비트 0) 위의 왼쪽 쉬프트 연산과 완전 동일합니다. 오른쪽으로 넘어간 비트들은 여전히 버려질 것이며 이동한 만큼 비어 있는 왼쪽 비트는 0으로 채우게 될 것입니다.
그러나 a가 음수라면 예기는 좀 달라 집니다.
-10 >> 2 연산은 아래와 같이 수행 됩니다. (2바이트로 표현한다고 가정 합니다)
11111111 11110110 (-10의 2진수 표현) 을 오른쪽으로 2칸씩 이동 시킵니다
11111111 11110110 데이터 범위를 넘어서 이동한 비트들은 버려집니다(빨간색 부분)
??111111 11111101 이동한 만큼 비어 있는 왼쪽 비트는 0 또는 1로 채워 집니다.
시스템에 따라 ?? 부분이 0으로 채워질 수도 1로 채워질 수도 있습니다.
음수를 유지하기 위해 1로 채우기도 하고, 양수의 비트 연산처럼 0으로 채우기도 합니다.
해당하는 시스템을 확인 할 필요가 있습니다.
Tip>>
<< (왼쪽 쉬프트) 연산을 사용하면 주어진 값의 배수를 쉽게(빠르게) 구할 수 있다.
<< 연산자를 이용하여 1칸씩 왼쪽으로 이동하면 계속해서 값의 2배가 된다.
ex> 15 << 1 = 30 , 15 << 2 = 60 .....
같은 의미로 >> (오른쪽 쉬프트) 연산을 사용하면 주어진 값을 2로 나눈 결과가 나온다.
>> 연산자를 이용하여 1칸씩 오른쪽으로이동하면 계속해서 값을 2로 나눈 결과가 나온다
단, 나눈 결과가 실수 이면 소수점 부분은 제외(절사) 된다.
ex> 30 >> 1 = 15 , 30 >> 2 = 7 , 30 >> 3 = 3
정수값의 부호를 바꾸고 싶으면 2의 보수를 사용하면 된다.
즉, 이 말은 정수값의 ~(NOT) : 1의 보수 값을 구해서 1을 더하면 2의 보수가 되는 원리를 이용하면 된다.
ex> (~-100) + 1 = 100
'SW개발' 카테고리의 다른 글
| 리터럴(Literal) 상수 (0) | 2023.10.27 |
|---|---|
| ASCII (0) | 2023.10.27 |
| 실수 연산, 어떻게 하시나요??? (0) | 2023.09.27 |
| +- m * n의 e승 (0) | 2023.09.27 |
| 실수 데이터의 표현 방식 - 부동소수점 방식 (0) | 2023.09.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두...
그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=530
---
(이 글은 닷넷 프레임워크 기반의 예제 및 개념입니다. 그러나 대부분의 개념은 언어와 무관합니다)
여러분들은 '실수 연산'을 할 일이 있나요?
간혹, 랜덤한 값을 계산하거나, 그래프를 그릴 때, 간혹 실수 연산을 할 일이 있을 겁니다
그러나 이 경우에는 정확한 결과가 나오지 않아도 되는 경우가 많습니다
따라서 질문을 다시 해 보죠
여러분들은 정확한 실수 연산을 할 일이 있나요?
다음의 코드의 실행 결과를 예상해 보세요
double a = 11.22;
double b = 11.10 + 0.12;
bool result = (a == b);
result 는'참' 일까요, '거짓' 일까요?
인간의 계산(?) 방식대로 하면, 11.10 + 0.12 = 11.22 이기 때문에 a, b 두 값은 같으니까, 결과는 '참' 이어야 겠죠
그러나 결과는 '거짓' 입니다
컴퓨터는 인간처럼 계산하지 않는다는 게 원인이죠
이와 관련해서 자세한 내용은, 다음의 제 글들을 확인해 주세요
-> 0.1 을 100 번 더해도 10이 되지 않는다?
-> 실수 데이터의 표현 방식 - 부동소수점 방식
-> +- m * ne
그러면, 위 코드에 의해, 컴퓨터가 계산한 결과를 볼까요?
실수의 부동소수점 표현을 보기 위해 C# 에서 Console.WriteLine 에 형식 문자열(E/e)로 16자리까지 봅시다
double a = 11.22;
double b = 11.10 + 0.12;
Console.WriteLine("{0:e16}", a);
Console.WriteLine("{0:e16}", b);

어떻습니까?
두 값은 엄연히 다릅니다. 이것이 바로 컴퓨터가 계산한 결과 입니다
위에 제시한 링크의 글들을 보셨다면 이유는 아셧을 겁니다
컴퓨터가 실수를 표현하는 부동소수점 방식은 특정한 식에 의해 최대한의 근사치 만을 표현하기 때문입니다
---------------------------------------------------------------------------------------------------
참고로, 우리나라 화폐단위는 (간편하게도) 소수점이 없죠.
미국 화폐의 경우 센트 단위가 있어, 화폐 계산 할 때 소수점 연산이 필요한 경우가 있습니다
돈이 걸린 문제는 민감하죠. 그래서 돈 계산에 실수가 사용된다면 정확한 결과를 보장해야 겠지요
그런데, 문제는 실수 연산은 정확하지 않다는 겁니다
더 정확하게 말하자면, 부동소수점 방식의 실수 연산을 정확하지 않다는 거죠
만일, 돈 계산과 같이, 실수 연산이 매우 정확해야 한다면 부동 소수점을 사용하면 안됩니다
대표적인 부동 소수점 데이터타입으로는 float(single) 과 double 이 있죠
즉 실수를 double 로 선언해서 돈 계산을 하면 안된다는 말입니다
가장 간편한(?) 방법은 decimal 데이터 타입을 사용하는 것이죠
msdn의 다음문구를 참고하세요
'Single 및 Double에서는 정확하지 않는 숫자가 Decimal에서는 정확하게 표시되는 경우가 있습니다(예: 0.2, 0.3).
Decimal에서는 부동 소수점에서보다 산술 연산이 더 느리지만 더 정확한 결과가 나타나므로 성능 감소를 감내할
만한 가치가 있습니다'
그리고 중요한 것은 현재 환경에 맞는 최적의 선택이죠. msdn은 이렇게 권고합니다
'Decimal 데이터 형식은 모든 숫자 형식 중 가장 느린 형식입니다. 데이터 형식을 선택하기 전에 정밀도와 성능 중
무엇이 더 중요한지를 충분히 검토해야 합니다'
따라서, (실수가 포함된) 회계계산에는 언어를 불문하고 decimal 을 많이 사용합니다
(한국 화폐 기준만 사용하시나요? 그렇다면, int64 로도 충분할 것입니다)
앞서 예제 코드를 double 대신 decimal 로 바꿔 봅시다
decimal a = (decimal) 11.22;
decimal b = (decimal)11.10 + (decimal)0.12;
bool result = (a == b);
Console.WriteLine(result.ToString());
Console.WriteLine("{0:e16}", a);
Console.WriteLine("{0:e16}", b);
결과입니다
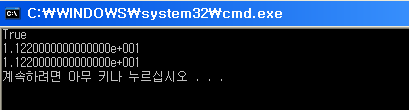
값이 같다는 결과를 보여주죠..
이제, 이 글에서 제가 하고 싶은 본론입니다
decimal 을 사용하지 않고도 실수 연산의 결과가 보장(?)되어야 한다는 경우가 있을 것입니다
음.. 사실 이 표현은 정확하지 않죠. 부동소수점 연산 자체가 이미 정확하지 않은데 어떻게 연산의 결과를
보장하겠습니까?
그러면 표현을 다르게 해 보죠
부동소수점 실수를 사용하고도 허용하는 범위 내에서는 결과가 (오차가 없다는 것을) 보장해야 한다
이러면 말이 되죠. 이러한 것을 내결함성 허용이라 합니다
부동소수점 실수 연산에서 연산의 결과가 차이나는 것은 컴퓨터의 실수 표현에 따른 미세한 오차 때문입니다
즉 이러한 미세한 차이는 허용할 수 있다는 가정입니다. 대부분은 이러한 미세한 차이는 허용가능합니다
잘 생각해 보세요. 0.1%의 오차도 허용하지 않겠다.... 라고 한다면 부동소수점 사용하면 안됩니다
실수 연산이 돈 계산만 아니면 (경우에 따라서는 돈 계산이라 할지라도),
어느 정도의 오차는 허용가능한 경우가 대부분입니다
0.1%의 오차 허용이 수치로 와 닿지 않나요?
그러면 특정 소수점 자리 수 까지만 정확성을 보장하면 되나요?
그렇다면, 부동 소수점으로도 충분히 연산 가능합니다
아래 코드는 0.%의 오차를 허용하는 환경에서의 두 값 비교 입니다
double a = 11.22;
double b = 11.10 + 0.12;
double difference = a * 0.0001; //0.1% 오차는 허용함
bool result = Math.Abs(a - b) <= difference; // true 반환
부동소수점 연산 결과의 오차는 특정한 범위 내에서는 허용가능한 경우가 많습니다
즉 컴퓨터가 부동소수점을 표현하는 방식에시 기인한 오차 범위 수준 정도는 무시해도 된다는 거죠
예를 들어, 소수점 2자리 까지만 사용하는 환경에서
0.0000001 오차 때문에 double 대신 decimal 을 사용한다는 것은 좀 오버 아닐까요???
MS 고객지원 사이트에는 다음과 같은 글이 있습니다
'서로 같은지 확인하기 위해 두 개의 부동 소수점 값을 비교하지는 마십시오.
반드시" 같아야 하는 두 숫자 사이에도 항상 약간의 차이가 납니다.
그 대신 항상 숫자들이 거의 근사한 값인지 확인하십시오.
즉, 두 수의 차이가 아주 작은지 또는 무의미한지 확인하십시오'
다음의 MS 자료들을 찬찬히 읽어 보시길 권장 드립니다
http://support.microsoft.com/kb/42980/ko
http://support.microsoft.com/kb/125056/ko
http://support.microsoft.com/kb/69333/ko
http://msdn.microsoft.com/ko-kr/library/c151dt3s.aspx
'SW개발' 카테고리의 다른 글
| ASCII (0) | 2023.10.27 |
|---|---|
| 비트(bit) 단위 연산 (0) | 2023.10.27 |
| +- m * n의 e승 (0) | 2023.09.27 |
| 실수 데이터의 표현 방식 - 부동소수점 방식 (0) | 2023.09.27 |
| 0.1 을 100 번 더해도 10이 되지 않는다? (0) | 2023.09.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두...
그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=99
---
앞에서 부동 소수점 방식에 대해 간략히 알아 봤습니다. 보통 프로그래밍 언어에서 실수형 데이터를 저장하기 위해
두가지 데이터 타입을 둡니다. float 와 double 이지요..
float : 단정도 부동 소수 (32비트)
double : 배정도 부동 소수 (64비트)
데이터를 표현하는데 사용되는 비트수가 다르기 때문에 당연히 표현가능한 수의 범위가 달라집니다.
컴퓨터는 실수형 데이터를 표현하기 위해 할당되어진 비트들 중 특정 비트를 지수,가수,부호로 사용함으로써
실수를 표현합니다. 이 두 형식 모두 앞서 살펴본 (아래의)부동 소수 표현식으로 표현됩니다.
+- m * n의 e승
+- : 부호
m : 가수
n : 기수
e : 지수
아래의 그림은 배,단정도 부동소수 저장시 사용되어 지는 메모리 구조 입니다.
1) 단정도 부동 소수의 메모리 구조(32 비트 사용)

2) 배정도 부동 소수의 메모리 구조(64 비트 사용)
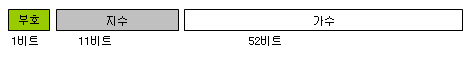
앞서, 우리는 위 표현식이 엄밀히 말하면 아래와 같다고 했습니다.
+- 1.m * 2의 e-127승
이유를 하나하나 살펴 봅니다.
[1] 기수는 2 이다
컴퓨터는 2진수를 사용하기 때문에 기수는 2가 되어 아래의 표현식으로 됩니다
+- m * 2의 e승
[2] 지수부는 excess 표현이 사용된다
지수부 역시 양수와 음수를 가져야 합니다.
10진수의 부동소수 표현에서 10의 지수 값으로 소수점의 위치가 변동 됨을 알 수 있습니다. 이는 2진수도 마찬가지
입니다. 즉, 지수부의 값이 - (마이너스) 가 되어야 할 필요가 있다는 말입니다. 그러나 지수부를 위한 메모리 공간에
는 별도의 부호 비트는 없습니다. 따라서 특별한 규칙을 만들어 마이너스를 표현하는데요...
이때 사용되는 것이 excess 표현입니다.
excess 표현은 지수부에서 나타낼 수 있는 최대 값을 반으로 나누어 그 값을 0 으로 보고
그것(0)보다 큰 값을 양수처럼, 작은값을 음수로 계산하는 것입니다.
(즉 최대값을 반으로 나눈 값을 기준으로 본다는 말이 됩니다)
한가지 예를 들어 보겠습니다.
단정도 부동소수인 float 에서 지수부를 위한 메모리 공간은 8비트 입니다.
8비트로 표현할 수 있는 최대 수는 11111111 이므로 10진수로 255 가 됩니다.
255 / 2 = 127.5 가 됩니다. 여기서 소수점 0.5는 버립니다.
즉 127을 0으로 취급합니다.
이때 지수부의 실제 값이 128이면 excess표현으로 인한 지수의 값은 1 이 되는 셈입니다
따라서 지수부의 값은 e-127 이 되느 것입니다.
+- m * 2의 e-127승
[3] 가수부는 특정 규칙을 사용하는 정규 표현을 사용한다
부동소수는 이미 알아본 바와 같이 다양한 형태로 표현될 수 있습니다.
10진수로 예를 들면 고정 소수 0.12 를 표현하기 위한 부동 소수는 아래와 같이 다양합니다.
0.12 = 0.12 * 10의 0승
0.12 = 12 * 10의 -2승
0.12 = 0.012 * 10의 1승
이와 같이 같은 수에 대한 표현방법이 다양하다면, 컴퓨터로 처리하기가 어려워 집니다. 따라서 특정한 표현방식
하나만 정해서 사용합니다. 위의 0.12 를 아래와 같이 하나의 표현 방식만 사용한다고 정해 둔다는 것입니다.
'소수점 이상은 0으로 하고, 소수점 이하 첫번째 자리는 0이 아닌 값으로 한다'
위의 규칙대로라면 0.12의 부동 소수 표현은 0.12 = 12 * 10의-2승 .. 이것만 가능 합니다.
이와 같이 특정 규칙을 정해 그 규칙대로만 표현하는 것을 정규 표현이라 합니다. 컴퓨터에서 2진수로 표현하는 부동소수 표현 방식에 이와 같은 규칙이 있습니다. '소수점 이상을 1로 고정한다' 라는 정규 표현을 사용합니다.
즉 반드시 정수부의 첫번째 자리는 1로 만들고 그 이상의 자리는 0으로 해주는 표현방법입니다.
소수점 이상을 1로 고정 하기 위해 2진수의 쉬프트 연산이 일어납니다. 또한 이렇게 고정한 1은 가수부의 표현
비트내에 포함시키지 않습니다. 정수부의 첫번째 자리는 반드시 1이라고 규칙을 정해 놓았기 때문에 별도의
비트가 필요치 않으며 가수부 비트내에 포함시키기 않음으로써 조금 더 넓은 범위의 수를 표현할 수 있게 됩니다.
(단정도 부동소수의 경우 23비트로 가수부를 표현하는데 첫번째 자리 1이 생략되었다고 할 수 있으므로 총 24비트
를 사용한다고 할 수 있을 것입니다)
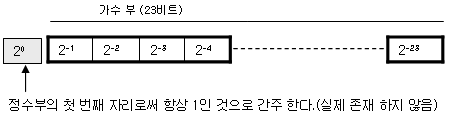
아래는 단정도 부동 소수에서 가수부의 정규 표현을 사용하여 표현한 것입니다.
1011.0011 <- 원래의 숫자
0001.0110011 <- 정수부의 첫번째 자리가 1이 되도록 오른쪽 쉬프트
0001.01100110000000000000000 <- 소수점 이하를 23비트로 만듦
01100110000000000000000 <- 소수점 이하만 뽑아 정규 표현을 완료
Example>>
2진수로 표현된 실수(단정도 부동소수)가 아래와 같다고 할때 10진수로 변환하면...?
0 01111110 10000000000000000000
부호 지수부 가수부
1) 부호비트가 0 이므로 양수입니다.
2) 지수부의 값이 126 이므로 (127 - 126) = -1 , 즉 2의 -1 승 , 0.5가 됩니다.
3) 가수부의 소수점 이상 첫번째 자리가 1이므로
위의 가수부의 값은 1.10000000000000000000000 이 됩니다.
즉 10진수로 1.5가 됩니다.
결론)
+- m * 2의 e승
이 표현식에 대입해 보면 + 1.5 * 0.5 = 0.75 가 됩니다
'SW개발' 카테고리의 다른 글
| 비트(bit) 단위 연산 (0) | 2023.10.27 |
|---|---|
| 실수 연산, 어떻게 하시나요??? (0) | 2023.09.27 |
| 실수 데이터의 표현 방식 - 부동소수점 방식 (0) | 2023.09.27 |
| 0.1 을 100 번 더해도 10이 되지 않는다? (0) | 2023.09.27 |
| 정수 데이터의 표현 방식 (0) | 2023.09.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두...
그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=98
---
컴퓨터가 정수를 표현하는 방식과 실수를 표현하는 방식은 크게 다릅니다.
실수 표현 방식을 이해하기 위해 아래와 같은 가정으로 출발하여 컴퓨터가 실수 표현을 하는 방식에 대해 알아
봅니다. 한가지 예를 들겠습니다.
만일 2바이트의 메모리로 실수를 표현한다고 가정할때, 가장 쉽게 생각해서 반을 나누어 1바이트에는 소수점
이상의 값을, 또 다른 1바이트에는 소수점 이하의 값을 저장한다고 칩시다. 아래와 같이 표현될 것입니다.
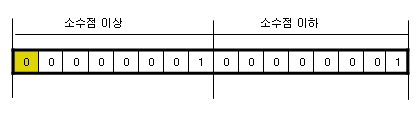
위와 같이 표현한다면 소수점 이상이 00000001 이므로 10진수 1이 되며, 소수점 이하는 00000001 이 되어 10진수
1이 되므로 +1.1 이 된다고 해석될 것입니다.
아주 심플하면서도 이해하기 쉽습니다. 그러나 컴퓨터는 일반적인 실수 표현을 위와 같은 방식을 채택하지는
않았습니다. 이유가 뭘까요?? (쉬운데 기냥 저렇게 하지-.-;)
이유는 바로 데이터의 표현한계입니다.
위와 같이 실수를 표현한다면 2바이트로 표현할 수 있는 실수의 범위는 아주 작습니다. 4바이트든, 8바이트든
실수 표현 범위의 한계를 가질 것입니다. 그렇다고 해서 아주 넓은 범위의 실수를 표현하기 위해 메모리를 확
늘려 데이터를 저장한다고 하면 해결책이 될까요?? 도대체 얼마나 많은 메모리를 요구해야 현실세계의 실수를
모두 표현 할 수 있을까요??
그래서 컴퓨터는 적은 수의 비트 수를 가지고 넓은 범위의 실수를 표현하기 위해서 하나의 식을 만들었습니다.
+- m * n의 e승
+- : 부호
m : 가수
n : 기수
e : 지수
위와 같은 식을 미리 정해 놓고 일부 비트는 가수로 일부 비트는 지수의 값을 정하는데 사용하여 실수를 표현합니다.
위의 식을 도입하여 적은 비트로 넓은 실수 범위를 표현가능 하다는 장점을 얻었지만 실수표현에서의 오차를 허용 할 수 밖에 없는 단점도 가지게 되었습니다. 앞서 살펴본 실수표현의 오차는 실제로 위의 식으로 기인하는 것입니다.
위와 같이 실수에서 소수점의 위치를 고정 시키는 것이 아니라 지수승에 따라 소수점이 움직일 수 있는 것을
부동 소수점 표현 방식이라고 합니다. (부동의 '부' 는 아닐 '부' 가 아닙니다. 둥둥 떠 다니는 '부' 입니다 ^^;)
위의 부동 소수의 표현 방식은 정확히 말해 아래와 같이 표현됩니다.
+- 1.m * 2의 e-127 승
즉 2진수에서 기수는 2이며 가수부와 정규표현과 지수부의 excess 표현이 사용된 것입니다.
이에 관해 다음에 자세히 알아 봅니다
참고>
우리가 사용하는 10진수에서도 고정,부동 소수점 표현방식으로 소수점을 표현을 달리 할 수 있습니다.
ex> 0.12 의 소수점을 가진 실수의 표현은 아래와 같이 다양합니다.
1)0.12 = 0.12 * 10의0승
2)0.12 = 12 * 10의-2승
3)0.12 = 0.012 * 10의1승
즉 고정소수점인 0.12 는 10의 지수승의 변화를 주어 다양한 부동 소수점 방식으로 표현 될 수 있습니다
'SW개발' 카테고리의 다른 글
| 실수 연산, 어떻게 하시나요??? (0) | 2023.09.27 |
|---|---|
| +- m * n의 e승 (0) | 2023.09.27 |
| 0.1 을 100 번 더해도 10이 되지 않는다? (0) | 2023.09.27 |
| 정수 데이터의 표현 방식 (0) | 2023.09.27 |
| 2진수 <-> 8 진수, 16 진수 변환 (0) | 2023.09.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두...
그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=97
---
너무나도 유명한 문구가 아닌가 싶습니다.
기초 C언어 공부할때나 프로그래밍 원리 같은 공부할때 꼭 등장하는 말입니다. 저도 그 말을 인용해 봤습니다.
이 말은 컴퓨터의 실수 표현 방식과 그에 따른 오차에 관한 말인데요.. 실제로 실수형 데이터의 연산에는 오차가
발생합니다. (직접해보세요.. 0.1 , 100 번 더하기)
이미 우리는 앞에 2진수로 표현된 수를 10진수로 변환하는 방법을 알고 있습니다. 그러면 2진수로 표현된 소수를
10진수로 변환하는 방법은요??? ... 마찬가지 입니다.
EX>2진수 1.01 을 10진수로 만들어 보겠습니다.
(2진수) 1.01 => 1*2의0승 + 0*2의-1승 + 1*2의-2승 = 1 + 0 + 0.25 = 1.25 (10진수)
이렇듯 2진수를 10진수로 표현할 때는 소수점을 기점으로 2의 (+,-)승을 해나가면 됩니다.
그렇다면 10진수 소수인 0.1 은 2진수로 어떻게 표현될까요???
소수점 이하 자리는 2의 마이너스 승이므로 2의 -1 승부터 차례로 해 보겠습니다
2의-1승 = 0.5 , 2의-2승 = 0.25 , 2의-3승 = 0.125 , 2의-4승 = 0.0625 ………
0.125 에서 바로 0.0625 로 넘어가 버렸습니다. 0.1은 나오지도 않았는데 말이죠..
물론 비트 자릿수를 늘려 이 들 숫자의 조합으로 0.1 에 가까운 수를 찾을 수는 있습니다만, 0.1이 아닌 근사값이
됩니다. 위의 산술과정은 비트자릿수를 하나씩 늘려서 0보다 큰 제일 작은 수를 나타낸 것인데요..
이런 방식이 아니더라도 소수점 이하 4비트를 가지는 메모리에서 표현되는 수를 다시 한번 보겠습니다.
소수점 이하 4비트를 가지는 2진수의 제일 작은 수 : 0.0000 => 10진수 0
소수점 이하 4비트를 가지는 2진수의 그 다음 작은 수 : 0.0001 => 10진수 0.0625
즉, 이 메모리로는 10진수 0과 0.0625 사이의 값은 표현할 수가 없습니다.
비트 수를 더 늘리면 더 좁은 간격의 수가 나올 수 는 있겠습니다만..
이렇듯 컴퓨터는 10진수 실수를 표현하는데 오차를 가집니다.
10진수에 해당하는 실수 값에 근사값을 나타낼 수 있을 뿐이지요..
결론적으로 0.1 이라는 값을 가지는 변수를 선언하면 그 변수에는 실제 0.1이 들어가는 것이 아니라 0.1의 근사값이
저장됩니다. 즉, 0.1의 근사값을 100번 더해봤지 10이 될리 없는 것입니다.
실제로 10진수 0.1을 2진수로 변환하면 0.00011001100....... (이하 1100 반복)이 됩니다
이런 수를 수학에서는 순환소수라 합니다.
대표적인 순환소수는 1/3 이 있습니다. 1/3 을 소수로 표현하면 0.33333.....(이하 3반복) 이 됩니다
참고>>
위의 내용은 문제를 간단하게 표현하기 위해 그리고 오차가 나는 이유를 이해하기 위해 2진수 소수 표현방식을 나타 냈습니다. 그러나 실제로 컴퓨터는 실수 표현을 단순히 소수점을 가진 2진수로 표현하지는 않습니다.
미리 말씀드리자면 일정한 식을 가지고 비트를 각 영역별로 나누어 저장,표현합니다. 이에 대해선 다음에 알아봅니다
'SW개발' 카테고리의 다른 글
| +- m * n의 e승 (0) | 2023.09.27 |
|---|---|
| 실수 데이터의 표현 방식 - 부동소수점 방식 (0) | 2023.09.27 |
| 정수 데이터의 표현 방식 (0) | 2023.09.27 |
| 2진수 <-> 8 진수, 16 진수 변환 (0) | 2023.09.27 |
| n 진수? 진수 변환 ! (0) | 2023.09.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두...
그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=96
---
이제 컴퓨터가 정수 데이터를 표현하는 방식에 대해 알아 봅니다.
* 데이터
컴퓨터가 표현 하는 모든 데이터는 2진수로 표현되는 것을 알고 있습니다. 이때 데이터란 정수나 실수처럼 수 일수도 있고 문자, 사운드, 동영상 등 컴퓨터가 표현하는 모든 것을 의미 합니다. 현재 이렇게 글을 작성하고 있는 것도 우리들 눈에는 문자로 보이지만 컴퓨터는 1 과 0 의 조합으로 인식합니다.
* 데이터 표현 단위
컴퓨터가 데이터를 나타내는 최소 단위는 비트입니다. 이 비트는 0 과 1 중 한 값을 저장할 수 있는 메모리 공간입니다.
이 비트들이 모여 바이트를 이루며 바이트가 모여 Kbyte 가 되며 Mbyte, Gbyte, 가 됩니다.
8 bit -> 1 byte 입니다. 아래는 8 bit(1byte) 메모리에 숫자 7이 저장된 모습입니다

1 비트에는 0 또는 1 을 표현할 수 있습니다. 이 말은 1 비트로 표현 가능한 수가 최대 2가지란 말이 됩니다.
1 + 1 비트, 즉 2 비트가 표현 할 수 있는 최대 가지 수는 ( 2 * 2) = 4 가지가 됩니다. 이와 같이 N 비트로 표현
할 수 있는 최대 데이터 가지 수는 2의 n 개가 됨을 알 수 있습니다
참고로 비트는 정보를 표현하는 최소 단위라고 하며 바이트는 문자를 나타내는 최소 단위라고 합니다
* 컴퓨터의 정수 표현 방식
정수란 0을 포함한 음과 양의 소수가 아닌 수를 의미합니다.
1. 양의 정수 표현 방식
닷넷에서의 대표적인 정수는 short 와 int 가 있습니다. 각각 2byte, 4byte 로 정수를 저장합니다
단, 모든 수의 가장 왼쪽 비트는 부호 저장용으로 사용됩니다. 이를 부호 비트라 합니다 (0 : 양수 , 1: 음수)
이 부호 비트를 MSB(Most Significant Bit) 라고 합니다
아래는 short 형 수 15 가 저장된 메모리 구조입니다 ( 노란색 비트는 부호비트 입니다)

2. 음의 정수 표현 방식
음수를 표현 할 때는 단순히 부호비트만 변경하면 되는 것이 아닙니다. 수학적으로 음수는 양수의 반대되는 값 ,
즉 양수N + 음수N = 0 이 되면 음수가 되는 것입니다. 컴퓨터는 이런 음수를 양수의 2의 보수로 표현합니다.
(물론 음수의 2의 보수는 다시 양수가 됩니다) 2의 보수 구하는 식 => 1의 보수 구하기 + 1 더하기 위의 15의 2의
보수를 구해 보겠습니다

'SW개발' 카테고리의 다른 글
| 실수 데이터의 표현 방식 - 부동소수점 방식 (0) | 2023.09.27 |
|---|---|
| 0.1 을 100 번 더해도 10이 되지 않는다? (0) | 2023.09.27 |
| 2진수 <-> 8 진수, 16 진수 변환 (0) | 2023.09.27 |
| n 진수? 진수 변환 ! (0) | 2023.09.27 |
| 개인정보의 암호화 대상 및 방법 (0) | 2020.07.28 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두...
그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=100
---
앞서 10 진수를 기준으로 2,8,16 진수의 변환을 알아 보았습니다.
이번에는 2진수를 8진수와 16진수로 변환하는 방법과
8진수,16진수를 2진수로 변환하는 방법을 알아 봅니다.
1. 2진수를 16진수로 변환하기.
2진수로 데이터가 저장되는 정보의 최소 단위인 비트가 4개 모이면 16진수 한 자리에 해당됩니다.
즉, 아래와 같이 4비트에 메모리에 저장할 수 있는 최대값은 15 가(16진수 f) 됩니다
|
1
|
1
|
1
|
1
|
(1 * 2의3승) + (1 * 2의2승) + (1 * 2의1승) + (1 * 2의0승) = 15(10진수) = F(16진수)
따라서 2진수 4자리는 16진수 한자리에 해당되므로
아래와 같은 2진수를 16진수로 변환 할때는 4자리씩 끊어서 16진수 한자리로 변환하면 됩니다.
11011111 = 1101 1111 = DF 가 됩니다.
또한 4자리로 끊었을때 자리수가 부족하면 0으로 채워서 계산하면 됩니다.
1101111 = 0110 1111 = 6F 가 됩니다.
그리고 소수점을 포함한 2진수도 마찬가지 개념으로 변환하면 됩니다.
1011.011 = 1011 . 0110 = B.6 가 됩니다.
2. 2진수를 8진수로 변환하기
위의 개념과 완전 동일합니다.
2진수 비트 3개는 8진수 한자에 해당 됩니다.
|
1
|
1
|
1
|
(1 * 2의2승) + (1 * 2의1승) + (1 * 2의0승) = 7(10진수) = 7(8진수)
따라서 2진수 3자리는 8진수 한자리에 해당되므로
아래와 같은 2진수를 8진수로 변환 할때는 3자리씩 끊어서 8진수 한자리로 변환하면 됩니다.
100101= 100 101 = 45 가 됩니다.
또한 3자리로 끊었을때 자리수가 부족하면 0으로 채워서 계산하면 됩니다.
10101 = 010 101 = 25 가 됩니다.
그리고 소수점을 포함한 2진수도 마찬가지 개념으로 변환하면 됩니다.
100101.1011 = 100 101 . 101 100 = 45.54 가 됩니다.
==================================================================
2진수를 8진수,16진수를 변환하는 방법에 대해 위에서 살펴 봤습니다.
그러면 그 역은, 8,16진수를 2진수로 변환하는 방법은 그저 먹기지요??
위 개념을 역으로 하면 될테지요..
별도의 설명이 필요 없겠으나 하나씩만 해 봅니다.
1. 16진수를 2진수로 변환하기
위에서 사용한 수를 가지고 해 봅니다.
위에서 2진수를 16진수로 변환할때 아래와 같았습니다.
11011111 = 1101 1111 = DF
16 진수 DF를 2진수로 변환할려면 16진수 한자리는 2진수 4자리에 해당되므로
D F = 13 15 = 1101 1111 가 됩니다.
소수점을 가지는 16진수도 완전히 동일하겠지요.. 예는 생략 합니다.
2. 8진수를 2진수로 변환하기
역시 위에서 사용한 수를 가지고 해 봅니다.
위에서 2진수를 8진수로 변환할때 아래와 같았습니다.
100101= 100 101 = 45
8진수 45를 2진수로 변환할려면 8진수 한자리는 2진수 3자리에 해당되므로
4 5 = 100 101 가 됩니다.
'SW개발' 카테고리의 다른 글
| 0.1 을 100 번 더해도 10이 되지 않는다? (0) | 2023.09.27 |
|---|---|
| 정수 데이터의 표현 방식 (0) | 2023.09.27 |
| n 진수? 진수 변환 ! (0) | 2023.09.27 |
| 개인정보의 암호화 대상 및 방법 (0) | 2020.07.28 |
| The Scale Cube (규모 확장성 모델) (0) | 2019.02.21 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두...
그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=95
---
우리가 작성하는 프로그램 코드가 실제 컴퓨터가 어떻게 인식하고 처리 하는지 아는 것은 지극히 기본이며 또한 아주 중요합니다. 실제로 우리가 작성하는 영어에 가까운 언어 문법의 코드 들은 (어떤 언어이든 간에) 컴퓨터는(정확히 말해 CPU는) 단 두가지 수로만 받아 들입니다.
바로 0 과 1 이지요..
인간 언어에 가까운(이를 고급언어라 합니다) C#이나 자바와 같은 언어들은 결국에는 0과 1 로 처리 됩니다. CPU가 처리 할 수 있도록 기계어로 변환 하는 과정은 각 언어의 컴파일러 가 담당하게 됩니다.아래에 컴퓨터 프로그래밍의 기본이 되는 2진수와 기타 진수,진수변환 등을 소개합니다.
* 컴퓨터가 데이터를 인식하는 방법
컴퓨터는 모든 데이터의 연산과 제어를 CPU라는 장치에서 수행합니다
이 CPU는 IC(Integrated Circuit, 집적회로) 의 한 종류입니다

IC 의 모든 핀은 직류 전압 0V 나 +5V 중 하나의 전압을 가집니다.즉, 핀 1개로는 두 가지 상태만 나타낼 수 있습니다.
핀에 전기가 흐를 때는 1 , 흐르지 않을 때는 0을 나타냅니다. 이러한 IC 특성은 컴퓨터의 모든 데이터를 0 과 1 , 즉 2 진수로 처리하게끔 만든 원인입니다.이렇듯 컴퓨터 내부의 트랜지스터가 on / off 상태인 2진수 상태만 기억하므로
컴퓨터는 이 값의 조합으로 모든 데이터를 표현, 처리 합니다
* N 진수
N 진수란 N 개의 숫자를 이용해서 모든 데이터를 표현한다라는 뜻입니다. (16진수의 경우 일부 문자도 포함)
앞서 컴퓨터는 모든 데이터의 표현 및 연산을 0 과 1로 처리한다는 것을 알았습니다. 즉, 0 과 1 두 숫자를 이용해서
데이터를 표현하기에 2진수라 합니다. 우리가 실생활에서 사용하는 10진수는 0 ~ 9 , 10 개의 숫자를 이용해서 모든 숫자를 표현합니다
1.10 진수
10 진수는 0 ~ 9 , 10 개의 숫자를 이용하여 데이터를 표현하는 방식입니다.
데이터 표현>>
0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9
10,11,12,13,14,15,16,17,18,19
……………………………
0 ~ 9 까지 점점 증가하다 9 다음은 다시 0 부터 시작합니다. 즉 9 다음에 자릿수가 증가합니다
2. 2 진수
2 진수는 0 과 1을 이용하여 데이터를 표현하는 방식입니다.
데이터 표현>>
0 , 1
10, 11
100,101,110,111
………………
2진수의 경우 한 자릿수 내에서 표현할 수 있는 최대 값이 1이므로 1 다음에 자릿수가 증가합니다
3. 16 진수
16 진수는 16개의 숫자로 데이터를 표현하는 방식입니다.
단, 숫자는 0 ~ 9 까지만 존재하므로 나머지 6개는 a ~ f 를 사용합니다
데이터 표현>>
0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f
10,11
……………………………..
16 진수의 경우 한 자릿수로 표현할 수 있는 수의 범위가 0 ~ f 이므로 f 다음에 자릿수가 증가합니다
4. 8 진수
8 진수는 8개의 숫자로 데이터를 표현하는 방식입니다
데이터 표현>>
0,1,2,3,4,5,6,7
10,11,12,13,14,15,16,17
8 진수의 경우 한 자릿수 내에서 표현할 수 있는 수의 범위가 0 ~ 7 이므로 7 다음에 자릿수가 증가 합니다.
* 진수 변환
컴퓨터는 2 진수만을 다루지만 사람들은 사용하기 편한 10 진수를 사용합니다. 10진수의 사용기원은 사람의 손가락이 10 개인대서 기원한다고 합니다. 사람들과의 의사소통에는 10진수 표현법으로 의사전달이 가능하지만 컴퓨터는 2진수만 취급합니다. 따라서 프로그래머들은 컴퓨터가 이해하는 2진수로의 변환을 알아야 합니다
10 진수<-> 2진수 나아가 N진수 <-> M 진수로의 변환에 대해 알아보겠습니다
1. 10 진수 <-> 2 진수
먼저 10진수를 2진수로 변환하는 방법을 알아봅니다. 10진수 7을 2진수로 변환합니다.
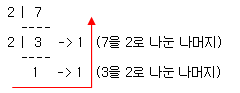
결과적으로 10 진수 7 은 2 진수 1 1 1 이 됩니다
이제 2 진수를 10 진수로 변경해 보겠습니다. 위의 2 진수 1 1 1 을 10 진수로 변경해 보겠습니다.
계산 방식은 각 자릿수를 2의 승으로 취합니다.
1 1 1 -> (1 * 2의2승) + (1 * 2의1승) + (1 * 2의0승) = 4 + 2 + 1 = 7
2. 10 진수 <-> 16 진수
우선 10 진수를 16 진수로 변경해 보겠습니다. 10 진수 97 을 가지고 변환해 보겠습니다. 계산 방식은 위의 2진수 변경과 동일합니다.

따라서 10 진수 97 은 16진수 61 이 됩니다.
이제 16 진수 61을 10 진수로 변경해 보겠습니다.
61 -> (6 * 16의1승) + (1 * 16의0승) = 96 + 1 = 97
3. 10 진수 <-> 8 진수
우선 10 진수를 8 진수로 변경해 보겠습니다. 10 진수 77 을 가지고 변환해 보겠습니다.

따라서 10 진수 77 은 8 진수 115 가 됩니다.이제 8 진수 115 를 10 진수로 변경해 보겠습니다
115 -> (1 * 8의2승) + (1 * 8의1승) + (5 * 8의0승) = 64 + 8 + 5 = 77
'SW개발' 카테고리의 다른 글
| 정수 데이터의 표현 방식 (0) | 2023.09.27 |
|---|---|
| 2진수 <-> 8 진수, 16 진수 변환 (0) | 2023.09.27 |
| 개인정보의 암호화 대상 및 방법 (0) | 2020.07.28 |
| The Scale Cube (규모 확장성 모델) (0) | 2019.02.21 |
| 해킹 피해에 따른 행정처분 사례 (0) | 2019.02.08 |
요즘 개인정보가 핫(hot)? 하다.
산업 전 분야에 걸쳐 개인정보가 주요한 비즈니스 데이터로 활용되고 4차 산업혁명의 인공지능, 빅데이터, 사물인터넷 등의 융/복합 기술 기반에는 방대하고 광범위한 데이터가 활용되는데 여기서 개인정보 역시 예외가 아니다.
하지만 무분별한 개인정보의 활용은 많은 부작용을 낳는 것도 사실이다.
기업이나 개인은 타인의 개인정보를 활용할 때, 자칫 잘 못 하면 법 방망이(?)에 후드려 맞을 수 있다는 것을 명심해야 한다.
보통 개인정보를 정보시스템에 저장 또는 송/수신할 때 암호화 해야 한다고 알고 있는데, 그 기준이 모호할 때가 많다.
"모든 개인정보를 암호화 해야 하는가? 개인정보의 범위는 어디까지 인가?"
이 글에서는, 법령과 행정규칙에 근거하여 개인정보의 개념을 이해하고 암호화 대상과 방법에 대해 알아보고자 한다.
By 개인정보보호법
'개인정보보호법'에서는 '개인정보'를 다음과 같이 정의하고 있다.
[개인정보보호법, 제2조(정의)]
"개인정보"란 살아 있는 개인에 관한 정보로서 다음 각 목의 어느 하나에 해당하는 정보를 말한다
- 성명, 주민등록번호 및 영상 등을 통하여 개인을 알아볼 수 있는 정보
- 해당 정보만으로는 특정 개인을 알아볼 수 없더라도 다른 정보와 쉽게 결합하여 알아볼 수 있는 정보. 이 경우 쉽게 결합할 수 있는지 여부는 다른 정보의 입수 가능성 등 개인을 알아보는 데 소요되는 시간, 비용, 기술 등을 합리적으로 고려해야 한다.
- 가명처리함으로써 원래의 상태로 복원하기 위한 추가 정보의 사용,결합 없이는 특정 개인을 알아볼 수 없는 정보(가명정보)
(참고) 가명처리
- 개인정보의 일부를 삭제하거나 일부 또는 전부를 대체하는 등의 방법으로 추가 정봅가 없이는 특정 개인을 알아볼 수 없도록 처리하는 것
법령 정의에 근거하여 개인정보를 해석하더라도, 개인정보의 범위는 매우 광범위 할 수 있으며 상황에 따라 해석이 달라질 수 있는 것을 알 수 있다
개인정보보호법의 '개인정보의 안전성 확보조치 기준'에서는 개인정보 암호화 대상 및 방법을 명시하고 있다.
[개인정보의 안정성 확보조치 기준, 제7조(개인정보의 암호화)]
- 고유식별정보/비밀번호/바이오정보를 정보통신망으로 송신하거나 보조저장매체 등을 통하여 전달하는 경우
- 비밀번호/바이오정보를 저장하는 경우(단 비밀번호를 저장하는 경우 복호화 되지 않도록 일방향 암호화 저장)
- 인터넷 구간 및 DMZ에 고유식별정보를 저장하는 경우
- 내부망에 고유식별정보를 저장하는 경우 다음 각 호의 기준에 따라 암호화 적용여부/범위 정하여 시행
- 개인정보 영향평가의 대상이 되는 공공기관의 경우 해당 개인정보 영향평가 결과
- 암호화 미적용시 위험도 분석에 따른 결과
- 개인정보를 암호화 하는 경우 안전한 암호알고리즘으로 암호화 저장
- 암호화된 개인정보를 안전하게 보관하기 위해 안전한 암호 키 생성, 이용, 보관, 배포 및 파기 등에 관한 절차 수립/시행
- 업무용 컴퓨터 또는 모바일 기기에 고유식별정보를 저장하여 관리하는 경우 상용 암호화 SW 또는 안전한 암호화 알고리즘을 사용
(고유식별정보)
- 주민등록번호 / 외국인등록번호 / 운전면허번호 / 여권번호
(암호화 미적용시 위험도 분석에 따른 결과)
- 개인정보처리시스템의 보호수준을 진단하여 암호화에 상응하는 조치를 했는지를 분석
- (참고) 개인정보 위험도 분석 기준 및 해설서
글로 나열된 법 조문으로는 한눈에 들어오지 않는다. KISA(한국인터넷진흥원)에서 발간한 '개인정보의 암호화 조치 안내서'의 요약표를 옮겨 보았다.

또한 해당 안내서에서는 안전한 암호 알고리즘을 안내하고 있다.
- 안전한 암호 알고리즘이란 국내 및 미국, 일본, 유럽 등의 국외 암호 연구 관련 기관에서 권고하는 암호 알고리즘을 의미
- 공공기관은 국가정보원의 검증대상 암호 알고리즘을 기반으로, 민간부문(법인,단체,개인)은 국내/외 전문기관(KISA, NIST, ECRYPT, CRYPTREC 등)이 권고하는 암호 알고리즘을 기반으로 개인정보보호법상의 개인정보 암호화에 사용할 수 있는 안전한 암호 알고리즘의 예시는 다음의 표와 같다.

By 정보통신망법
개인정보보호법 뿐만 아니라, 정보통신망법에서도 '개인정보의 기술적/관리적 보호조치 기준'을 통해 개인정보 암호화에 대한 행정 규칙을 명시하고 있다.
[개인정보의 기술적/관리적 보호조치 기준, 제6조(개인정보의 암호화)]
- 비빌번호는 복호화 되지 않도록 일방향 암호화해서 저장
- 다음 각 호의 정보를 안전한 암호알고리즘으로 암호화해서 저장
- 주민등록번호
- 여권번호
- 운전면허번호
- 외국인등록번호
- 신용카드번호
- 계좌번호
- 바이오정보
- 개인정보 및 인증정보를 송/수신할 때에는 안전한 보안서버 구축 등의 조치. 보안서버는 다음 각 중 하나의 기능을 갖추어야 함
- 웹서버에 SSL 인증서를 설치하여 전송 정보 암호화 송/수신 기능
- 웹서버에 암호화 응용프로그램을 설치하여 전송 정보 암호화 송/수신 기능
- 개인정보를 컴퓨터, 모바일 기기 및 보조저장매체 등에 저장할 때에는 암호화
개인정보보호법과 거의 유사하지만, 암호화 대상에 있어 두 가지(신용카드번호, 계좌번호)가 추가되어 있는 것을 확인할 수 있다.
결론
지금까지 관련 법령(개보법/정통망법)과 행정규칙을 살펴 보았는데, 쉽게 풀어서 결론 지으면 다음과 같다.
1. 고유식별정보(주민등록번호/운전면허번호/여권번호/외국인등록번호)와 비밀번호, 바이오정보는 무조건 암호화
(내부망 저장시 예외가 있긴 하나, 이는 한정된 기관(일부 공공기관 등)에 한하므로 패스. 상세한 내용은 위의 표 참조)
2. 암호화 할 때는 안전한 암호화 알고리즘을 사용
(안전한 알고리즘은 위에 표 참조)
3. 비밀번호는 (복회화 되지 않도록) 일방향 (해쉬) 암호화
4. 정통망법 적용 사업자는 추가로 신용카드번호, 계좌번호도 암호화
(주의)
이 글에서는 두개의 법(개보법/정통망법)만을 참조하여 작성되었습니다.
분야별로 법 적용이 다를 수 있으므로 사업자별로 적용받는 법(신용정보법, 위치정보법 등)을 추가로 확인해야 할 수도 있습니다.
(참고) FAQ
KISA가 발간한 '개인정보 암호화 조치 안내서'에는 실무자들이 암호화 조치 관련하여 자주 궁금해 하는 점들을 부록의 FAQ로 안내하고 있는데, 여기에 그 내용을 옮겨와 본다.
[Q1] . 개인정보 보호법 상의 암호화 대상은 무엇이며 어떻게 암호화해야 하나요?
개인정보 보호법상 암호화 대상은 고유식별정보(주민등록번호, 외국인등록번호, 운전면허번호, 여권번호), 비밀번호, 바이오정보입니다. 암호화 대상 정보를 전송시 그리고 저장시 아래 표에 따라 암호화하여야 합니다

[Q2]. 공공기관입니다. 개인정보처리시스템의 DBMS (DataBase Management System)에서 제공하는 TDE(Transparent Data Encryption) 방식을 사용한 암호화가 개인정보 보호법에 위배됩니까?
개인정보 보호법 관점에서는 개인정보의 안전성 확보조치 기준(고시)에 따라 고유식별정보 암호화시 안전한 알고리즘을 사용하도록 하고 있습니다. TDE 방식에서 안전한 알고리즘을 사용하여 암호화한다면 법 위반 사항이 아닙니다. 다만, 공공기관은 전자정부법에 따라 국가정보원이 안전성을 확인한 암호모듈 또는 제품을 우선 적용하여야 하며 자세한 사항은 해당 기관에 적용되는 관련 법령, 고시, 규정, 지침 등을 확인하시기 바랍니다
[Q3]. 암호화 관련하여 우리 기관(공공, 민간)에 적용되는 규정·지침과 개인정보보호법에서 적용하는 암호화 요구사항이 서로 다를 때 어느 것을 적용해야 하나요?
개인정보 보호법 및 시행령, 고시에서 규정한 암호화 요구사항을 준수하면 개인정보 보호법상 암호화 의무는 준수한 것입니다. 본 고시 준수로 인하여 다른 규정·지침을 준수하기 어렵게 된다면 “개인정보 보호법”은 준수 하였으나 해당 규정·지침은 위배한 것이 될 수 있습니다. 따라서, 최선의 방법은 개인정보 보호법과 해당 기관에 적용되는 규정·지침에서 요구하는 암호화 관련 사항 모두를 준수하는 것이라 할 수 있습니다.
[Q4]. 안전한 암호 알고리즘에는 어떤 것들이 있나요?
안전한 암호 알고리즘은 국내·외 전문기관에서 권고하고 있는 알고리즘으로서 본 안내서의 ‘[참고 1] 국내·외 암호 연구 관련 기관의 권고 암호 알고리즘’, ‘[참고 2] 국가정보원 검증대상 암호 알고리즘 목록’의 내용을 참고하시기 바랍니다
[Q5]. 대칭키 암호 알고리즘 DES나 해쉬함수 MD5를 사용하면 안 됩니까?
DES와 MD5와 같은 암호 알고리즘의 경우 안전성 유지가 어려우므로 안전한 암호 알고리즘으로 볼 수 없어 권고하고 있지 않습니다. 안전한 암호 알고리즘은 본 안내서의 ‘[참고 1] 국내·외 암호 연구 관련 기관의 권고 암호 알고리즘’, ‘[참고 2] 국가정보원 검증대상 암호 알고리즘 목록’ 내용을 참고하시기 바랍니다.
[Q6]. DB에 저장된 주민등록번호를 일부분만 암호화해서 저장해도 되는 것인지요?
예, 일부분 암호화가 가능합니다. 시스템 운영이나 개인 식별을 위해 해당 정보를 활용해야 하는 경우 생년월일 및 성별을 포함한 앞 7자리를 제외하고 뒷자리 6개 번호를 암호화 하여 사용할 수도 있습니다.
[Q7]. 암호화해야 하는 바이오정보의 대상은 어디까지 인지요?
암호화하여야 하는 바이오정보는 식별 및 인증 등의 업무절차상 수집이 명확한 경우로 한정되며, 이와 무관하게 수집되는 이미지, 녹취 정보 등은 암호화 대상에서 제외됩니다. 예를 들어, 콜센터 등에서 업무절차상 주민등록번호 수집이 명확한 경우의 음성기록은 암호화 해야 하나, 단순 상담 시 저장되는 음성기록 등은 암호화 대상에서 제외될 수 있습니다.
[Q8]. 안전한 대칭키 암호화 알고리즘 사용시 암호키(비밀키)의 길이는 어떻게 설정해야 하나요?
암호키의 길이가 짧거나 사용되는 문자의 종류를 섞어 쓰지 않으면 암호화가 되었더라도 공격자가 쉽게 암호 해독을 할 수 있습니다. 암호해독이 어렵도록 암호키 설정시 문자, 숫자, 특수문자 등의 문자조합 방법과 문자열 길이, 사용기간 등의 암호키 작성 규칙을 정하여 운영하는 것이 바람직합니다. 특히 잘 알려진 영문자, 숫자(1234, 123456, love, happy, admin, admin1234) 등은 쉽게 유추 할 수 있으므로 사용하지 않도록 주의해야 합니다.
[Q9]. 회사에 고객들의 이름, 주소, 전화번호, 이메일, 비밀번호를 저장하고 있습니다. 암호화 대상이 무엇인가요?
개인정보의 안전성 확보조치 기준 고시에서 암호화 대상은 고유식별정보(주민등록번호, 여권번호, 운전면허 번호, 외국인등록번호), 비밀번호, 바이오정보입니다. 특히, 비밀번호의 경우에는 일방향(해쉬) 암호화하여 저장하시면 됩니다
[Q10]. 부동산중개업을 하고 있습니다. 업무용 컴퓨터에 한글, 엑셀을 이용하여 주민등록번호를 처리 하고 있습니다. 암호화를 어떻게 해야 합니까?
PC에 저장된 개인정보의 경우 상용프로그램(한글, 엑셀 등)에서 제공하는 비밀번호 설정기능을 사용하여 암호화를 적용하거나, 안전한 암호화 알고리즘을 이용하는 소프트웨어를 사용하여 암호화할 수 있습니다.
※ 한컴 오피스 : 파일 >> 다른이름으로 저장하기 >> 문서 암호 설정에서 암호 설정 가능 ※ MS 오피스 : 파일 >> 다른이름으로 저장하기 >> 도구 >> 일반옵션에서 암호 설정 가능
[Q11]. A사가 개인정보처리시스템을 위탁하거나, ASP(Application Service Provider), 클라우드 서비스를 이용하는 경우 암호화 수행을 누가 해야 하나요?
개인정보의 암호화 등 안전성 확보조치는 원칙적으로 “개인정보처리자”의 의무입니다. 따라서 개인정보 처리시스템을 위탁하거나 ASP를 이용하는 경우에도 암호화 조치사항에 대한 이행여부에 대한 책임은 위탁기관인 A사가 지게 됩니다. 다만, A사는 암호화에 대한 요구사항을 A사의 위탁을 받은 수탁기관(ASP, 클라우드 서비스 제공자 등)과의 계약서 등에 명시하여 수탁기관으로 하여금 암호화를 처리하게 요구할 수 있습니다.
'SW개발' 카테고리의 다른 글
| 2진수 <-> 8 진수, 16 진수 변환 (0) | 2023.09.27 |
|---|---|
| n 진수? 진수 변환 ! (0) | 2023.09.27 |
| The Scale Cube (규모 확장성 모델) (0) | 2019.02.21 |
| 해킹 피해에 따른 행정처분 사례 (0) | 2019.02.08 |
| [웹보안] SQL Injection (1) | 2019.01.28 |
INTRO
일정 규모 이상의 정보 서비스를 제공하고 있다면, 아마도 대부분 한대 이상의 서버를 배치하여 부하분산을 시키고 있을 것입니다. 이런 배치 전략을 로드밸런싱이라고 하죠.

로드밸런싱은 대량의 트래픽을 수용하기 위해 여러대의 (동일한) 서버가 요청을 나눠서 처리하도록 하는 부하분산을 통해 서비스의 처리량을 증가 시키고자 하는 것이 주 목적입니다.
물론 로드분배 알고리즘과 서버 상태를 기반으로 해서 고가용성(HA)의 요건도 같이 충족되는 것이 일반적입니다.
만일 트래픽이 점점 더 늘어난다면, 그에 맞춰 Service #4, Service #5, ... 이런식으로 서비스의 복제본을 늘려 나가기만 하면 되기 때문에 손쉽게 확장이 가능합니다.
애플리케이션의 확장성을 보장하기 위해서는 다양한 전략을 구사할 수 있습니다. 로드밸런싱은 그 중에서도 트래픽의 처리량을 증가시켜서 서비스의 능력을 향상하는 아키텍처 전략에 해당합니다.
이 글에서는 애플리케이션의 확장성 보장을 위한 다양한 전략을 'Scale Cube'라는 규모 확장성 모델에 근거하여 설명하고자 합니다.
확장성
먼저 소프트웨어 분야의 확장성이라는 개념을 먼저 정리하자. 확장성은 쉽게 말해서,
애플리케이션이 얼마나 손쉽게 확장될 수 있는 가에 대한 가능성에 대한 정도로써 애플리케이션의 여러 품질속성 중 하나이다.
확장성이 좋다는 말은, 애플리케이션의 능력을 손쉽게 향상 시킬수 있다는 의미가 된다.
여기서 애플리케이션의 능력이란, 알고리즘이나 로직과 같은 세부적인 기능 측면보다는 성능/가용성/보안과 같은 비기능적인 요소(이를 품질속성이라 함)에 해당하는 능력을 말한다.
'정보통신기술용어해설'에서는 확장성을 다음과 같이 정의하고 있다.
대규모적인 재설계/재설치 등의 필요없이 확장이 얼마나 쉽고 가능한가에 대한 용이성
확장의 대상과 확장 방식에 따라 확장성을 다음과 같이 세분화 할 수 있다.
1) 규모 확장성
일반적으로 모든 확장성은 규모 확장성을 의미한다. 규모란 용어는 양적인 측면의 크기를 지칭하는 용어로써 특정 대상만을 한정하지는 않는다. 예를 들어 트래픽 처리량에 대한 규모, 데이터 보관량에 대한 규모, 기능의 종류와 양에 대한 규모 등 얼마든지 수식이 가능하다.
다만, 여기서의 규모 확장성은 아래에 설명하는 다른 확장성과 구분하기 위해 트래픽 처리량에 대한 확장으로 한정하고자 한다.
규모 확장성을 보장하기 위해서는 앞서 살펴본 로드밸런싱과 같이, 동일한 기능을 수행하는 애플리케이션의 복사본을 여러대 구성하여 트래픽 부하를 나눠 가지도록 구성한다. 이런 구성을 Scale out(수평 스케일)이라고도 하며 손쉽게 트래픽 처리량을 확장할 수 있어 흔히 사용되는 방법이다.
규모 확장성을 보장하는 로드밸런싱의 구조를 다시 확인해 보자. Service #1~#3은 모두 동일한 복제본으로 동일한 기능을 수행한다.
2) 기능 확장성
애플리케이션의 기능을 얼마나 손쉽게 추가, 수정할 수 있느냐에 대한 정도이다. 다시 말해, 기존 기능을 확장하거나 새기능을 추가하여 애플리케이션의 능력을 향상시킬 수 있는 가능성에 대한 정도로 풀어 쓸 수 있다.
과거 유행했던 SOA(Service Oriented Architecture)와 근래 유행하는 MSA(Micro Service Architecture)가 바로 기능 확장성 보장하는 아키텍처 구조이다.
MSA는 애플리케이션을 기능 및 역할 관점에서 분리하여 개별 서비스로 구성하고 상호 연동을 통해서 전체 애플리케이션을 구성하는 방식으로 애플리케이션의 독립성과 자율성을 보장함으로써 유지보수와 기능 확장을 용이하게 하는 아키텍처 구조이다.
다음 그림은 애플리케이션이 역할 단위로 분리되어 서로 다른 기능을 제공하는 모습을 보여준다.

3) 데이터 확장성
각각의 애플리케이션이 데이터의 일부분만을 책임지도록 하여 처리 효율을 증가시키거나 데이터 규모에 대한 확장성을 확보하는 기법이다. 데이터 샤딩이나 파티셔닝같이 데이터 자체를 분리하여 저장하는 방식으로 많이 활용되며 경우에 따라서는 애플리케이션 단위의 파티셔닝을 통해 각각이 애플리케이션이 서로 다른 데이터 영역을 책임지게 함으로써 데이터의 처리효율과 애플리케이션의 처리 성능을 향상시킬 수 있다.
다음 그림은 서로 다른 데이터가 서로 다른 저장소에 분리되어 저장된 샤딩된 구조를 보여준다.
여기서 각 Application은 모두 동일한 복제본으로 동일한 기능을 실행하지만 책임지는 데이터 영역이 서로 다르다.

예를 들어, 대량의 데이터에 대한 검색 기능을 개발한다고 할 경우, 다음과 같이 검색 API를 두고 뒷단으로 애플리케이션을 파티셔닝해 그 결과를 조합해서 반환하도록 구성할 수도 있다.

The Scale Cube
'THE ART OF SCALABILITY'라는 책에서는 매우 유용한 3가지 차원의 규모 확장성 모델을 제시한다고, 'Chris Richardson'이 서술한 바 있다.

상단의 그림은 Chris Richardson의 The Scale Cube라는 글에서 발췌해온 것이다. Chris Richardson은 해당 글에서 각 축(axis)에 대해서 설명한다. 글이 짧지만 핵심을 잘 전달해 주고 있으니 일독해 보기를 권장한다.
어느 훌륭한 한국분이 이 글을 번역해서 올려 뒀으니 참고 바란다.
> 스케일 큐브 (크리스 리차드슨)
X축 확장
애플리케이션의 동일한 복제본을 다수로 구성하여 애플리케이션의 처리 능력을 향상시키는 기법이다.
앞서 살펴본 처리량에 대한 확장성 즉, '규모 확장성'이 바로 이 축에 해당한다.
Y축 확장
애플리케이션의 기능을 역할별로 분리하여 서로 독립적인 서비스로 구성하는 기법이다.
앞서 살펴본 '기능 확장성'이 바로 이 축에 해당한다.
Z축 확장
데이터이 일부만을 책임지도록 하여 데이터 저장과 활용 관점에서 애플리케이션의 처리 능력을 향상시키는 기법이다. 앞서 살펴본 '데이터 확장성'이 바로 이 축에 해당한다
확장성 모델 요약
각각의 확장성 모델을 다음과 같이 하나의 표로 정리해 보았다.

실무 환경
실제 실무환경에서는 각각의 확장성 축이 모두 혼합되어 구성되는 것이 일반적이다. 특히 MSA 아키텍처 구조를 표방하는 애플리케이션들은 거의 대부분 아래와 같은 구조로 설계된다. 즉 모든 축의 확장성을 보장하는 형태로 구성하여 극강의(?) 확장성을 확보한다.

'SW개발' 카테고리의 다른 글
| n 진수? 진수 변환 ! (0) | 2023.09.27 |
|---|---|
| 개인정보의 암호화 대상 및 방법 (0) | 2020.07.28 |
| 해킹 피해에 따른 행정처분 사례 (0) | 2019.02.08 |
| [웹보안] SQL Injection (1) | 2019.01.28 |
| [웹보안] 브루트 포스(BRUTE FORCE) 공격 (2) | 2019.01.23 |
INTRO
근래 대부분의 해킹 사고는 개인정보 유출과 직결됩니다.
해커는 기업이 보유하고 있는 고객의 개인정보를 불법적으로 탈취하여 금품을 요구하거나 탈취한 개인정보를 또다른 불법적인 용도로 활용하게 됩니다.
따라서 기업의 해킹 사고는 (그들만의 문제가 아니라) 그 피해가 우리와 같은 일반 이용자게까지 미치게 되는 것입니다.

이에 현행 법제도에서는 기업이 제대로 관리/감독 하지 않아서 발생한 개인정보 유출 사고에 대해 과징금, 시정명령, 손해배상과 같은 행정처분을 부과할 수 있는 법적 근거를 마련해 두고 있습니다.
이번 글에서는 법에서 명시하고 있는 행정처분의 규정을 살펴보고, 그간 실제 발생한 해킹사고에서 기업에게 부과된 행정처분 사례를 알아 보겠습니다.
개인정보 보호 관련 법체계
개인정보보호와 관련된 가장 보편적인 법은 '개인정보보호법'이다.
개인정보보호법은 2011년 3월 29일 처음 제정/공포되어 6개월 뒤인 2011년 9월 30일에 첫 시행된 이후 지금까지 지속적인 법개정을 거듭하고 있다.
또한 정보통신망법(정보통신망 이용촉진 및 정보보호 등에 관한 법률)과 신용정보법(신용정보의 이용 및 보호에 관한 법률) 등에서도 개인정보 활용과 보호에 대한 법적 규정을 따로 마련해 두고 있다.
특별법 우선 원칙
법은 크게 일반법과 특별법으로 나뉜다.
특정한 대상(지역/사람/사항 등)에 제한없이 적용되는 법을 일반법이라 하고, 특정한 지역/사람/사항 등에 국한하여 적용되는 법을 특별법이라 한다.
예를들어, 모든 지역의 모든 사람에게 공통으로 적용되는 형법, 민법과 같은 법은 일반법에 해당하며, 특정 대상에 국한하여 적용되는 김영란법, 아동청소년법 등은 특별법에 해당한다.
특별법은 일반법에 우선하여 적용되는데 이를 '특별법 우선 원칙'이라 한다.
개인정보보호법 6조에서도 다음과 같이 법률간 관계를 규정하고 있다.
개인정보보호법 제6조(다른 법률과의 관계) (법조문 바로가기)
개인정보 보호에 관하여는 다른 법률에 특별한 규정이 있는 경우를 제외하고는 이 법에서 정하는 바에 따른다.
다시 말해 일반법과 특별법에 중복된 규정이 존재할 경우, 특별법이 우선 적용되며 특별법에 존재하지 않는 규정에 대해서만 일반법이 적용되는 체계이다.
앞서 설명한 개인정보 보호 관련 법들도 이런 체계를 따른다.
개인정보보호법은 개인정보를 다루는 곳이라면 누구에게나 구분없이 적용되는 일반법이며, 정보통신사업자에게 적용되는 정보통신망법은 특별법에 해당한다.
[출처: 금융위원회(2016)]

상단의 그림과 같이 기업의 업종에 따라 법 적용이 구분된다. 따라서 해킹 사고로 인해 개인정보가 유출된 경우, 기업이 어떤 처벌을 받게 되는지 알고 싶을 경우에는 해당 기업이 어떤 법에 적용을 받는지 파악해야 한다.
이 글에서는 정보통신망법에 초점을 맞춰 알아 볼 것이다.
개인정보 유출에 대한 법적 규제(행정처분 근거 법령)
개인정보 유출로 이어지는 해킹 사고 발생시, 해당 기업을 규제할 수 있는 법적 근거에 대해 알아보자. 다음 그림은 개인정보보호법과 정보통신망법을 기준으로 적용 가능한 법적규제와 조문을 보여준다.

행정처분 중 과징금 부과에 대한 법규정을 살펴보면 다음과 같이 기술하고 있다.
개인정보보호법 제34조의 2(과징금의 부과 등) (법조문 바로가기)
① 행정안전부장관은 개인정보처리자가 처리하는 주민등록번호가 분실ㆍ도난ㆍ유출ㆍ위조ㆍ변조 또는 훼손된 경우에는 5억원 이하의 과징금을 부과ㆍ징수할 수 있다. 다만, 주민등록번호가 분실ㆍ도난ㆍ유출ㆍ위조ㆍ변조 또는 훼손되지 아니하도록 개인정보처리자가 제24조제3항에 따른 안전성 확보에 필요한 조치를 다한 경우에는 그러하지 아니하다.
정보통신망법 제64조의3(과징금의 부과 등) (법조문 바로가기)
① 방송통신위원회는 다음 각 호의 어느 하나에 해당하는 행위가 있는 경우에는 해당 정보통신서비스 제공자등에게 위반행위와 관련한 매출액의 100분의 3 이하에 해당하는 금액을 과징금으로 부과할 수 있다.
...
6. 이용자의 개인정보를 분실·도난·유출·위조·변조 또는 훼손한 경우로서 제28조 제1항 제2호부터 제5호까지(제67조에 따라 준용되는 경우를 포함한다)의 조치를 하지 아니한 경우
...
핵심은 이렇다.
다른 사람(이하 이용자)의 개인정보를 수집하고 이를 활용하는 자(이하 서비스 제공자)는 이용자의 개인정보를 안전하게 보관하고 처리해야 할 의무가 있다.
만일 (1)개인정보 유출 사고가 발생 했을 때, (2)서비스 제공자가 개인정보 보호를 위한 안전조치의 의무사항을 소홀히 했을 때, 과징금을 부과할 수 있도록 한 것이다.
즉 아래의 두 조건이 모두 만족되었을 때, 과징금 부과가 가능한 것이다.

서비스 제공자 입장에서는 개인정보가 유출되었다 할지라도, 개인정보 보호를 위한 안전 조치를 충실히 했다는 것이 증명되면 과징금 처분을 감경받거나 면제 받을 수 있다는 말이 된다.
그렇다면, 서비스 제공자는 어떤 안전조치 의무사항을 준수해야 할까? 이 역시 법과 시행령을 통해 구체적으로 그 기준을 명시하고 있다.
정보통신망법 기준으로 보면, '제28조(개인정보의 보호조치) 제1항 제2호~제5호'까지의 조치를 해야 한다고 명시하고 있다.
정보통신망법 제28조(개인정보의 보호조치) (법조문 바로가기)
① 정보통신서비스 제공자등이 개인정보를 처리할 때에는 개인정보의 분실ㆍ도난ㆍ유출ㆍ위조ㆍ변조 또는 훼손을 방지하고 개인정보의 안전성을 확보하기 위하여 대통령령으로 정하는 기준에 따라 다음 각 호의 기술적ㆍ관리적 조치를 하여야 한다.
...
2. 개인정보에 대한 불법적인 접근을 차단하기 위한 침입차단시스템 등 접근 통제장치의 설치ㆍ운영
3. 접속기록의 위조ㆍ변조 방지를 위한 조치
4. 개인정보를 안전하게 저장ㆍ전송할 수 있는 암호화기술 등을 이용한 보안조치
5. 백신 소프트웨어의 설치ㆍ운영 등 컴퓨터바이러스에 의한 침해 방지조치
...
또한 28조의 각호에 대한 기술적, 관리적 조치에 대한 구체적인 안전조치 방법은 동법 '시행령 제15조(개인정보보호조치)'에 따를 것을 규정하고 있다.
서비스 제공자는 해당 법과 시행령을 기준으로 안전조치 의무를 충실히 해야만 개인정보 유출 사고가 발생해도 무거운 처벌을 받지 않게 된다.
과징금 산정 기준
서비스 제공자에게 금전적인 행정처분은 과징금과 과태료를 통해 이뤄진다.
과징금과 과태료 모두 법을 통해 그 산정 기준을 명시하고 있으며, 과태료 보다는 과징금이 더 무거운 처분에 해당하고 금액도 훨씬 높게 책정된다.
각 법에서는 다음과 같이 과징금 부과 기준을 규정하고 있다.
개인정보보호법(제34조의 2)
: 주민등록번호 유출시 5억원 이하의 과징금 부과정보통신망법(제64조의3)
: 위반행위와 관련한 매출액의 100분의 3 이하에 해당하는 금액을 과징금으로 부과
정보통신망법의 경우 매출액이 클 수록 과징금 금액도 비례해서 높게 책정되도록 규정하고 있다.
과징금의 구체적인 산정기준을 명시하고 있는 시행령을 살펴보면 다음과 같다.
정보통신망법 시행령 제69조의2(과징금의 산정기준 등) (법조문 바로가기)
① ...(생략) "위반행위와 관련한 매출액"이란 해당 정보통신서비스 제공자등의 위반행위와 관련된 정보통신서비스의 직전 3개 사업연도의 연평균 매출액을 말한다.
종합해보면, 직전 3개년도 연평균 매출액의 최대 3%까지 과징금을 부과힐 수 있다는 말이다.
과징금의 가중 및 감경
법 위반행위의 동기 및 내용, 위반의 정도와 결과 등을 고려하여 과징금을 가중하거나 감경할 수 있다.
또한 해킹 사고로 개인정보가 유출되었을 경우, 자진 신고하면 추가 감경을 해 준다. 관례로 보면 통상 10% 정도 추가 감경을 해 준다.
과징금의 구체적인 산정절차와 가중/감경에 대한 상세한 규정은 정보통신망법 시행령 제69조의2 제4항에 명시한 [별표 8]에서 확인할 수 있다
-> (바로가기) [별표 8] 과징금의 산정기준과 산정절차(제69조의2제4항 관련)
개인정보 유출 통계
지난해(2018년) 행정안전부와 KISA(한국인터넷진흥원)이 공동발간한 '개인정보 실태점검 및 행정처분 사례집'에서는 개인정보보보법이 시행(2011년 9월) 된 이후부터 2017년 말까지의 개인정보 유출 통계를 보여준다.

공공기관과 민간 기업을 합해 총 1억 3,254만건이 유출되었다. 2018년 데이터와 신고하지 않은 건수 까지 합한다면 더 높은 수치를 예상해 볼 수 있다.
5천만명 인구에 1억을 훨씬 상회하는 건수로 유출되었으니 적지 않은 수이다. 물론 중복이 존재하겠지만, 그래도 거의 대부분의 국민의 개인정보가 털렸다고 봐야 되지 않을까 한다.
잊을만 하면 터지는 개인정보 유출 사고와 대량의 유출 건수는, 역설적으로 개인정보 유출에 대한 경각심을 둔화 시키는 결과로까지 이어지는 듯 하다. 대부분의 사람이 자신의 개인정보가 불법적인 유통 경로로 거래되고 있다고 생각할 것이다.
개인정보 보호를 위해 개개인의 신중함도 필요하지만, 그에 앞서 개인정보를 활용하는 서비스 제공자의 보안의식 고취와 견고한 안전조치가 선행되어야 할 것이다.
동(同) 자료의 또 다른 통계(유출 사고 유형별 현황)을 보면 개인정보 유출 사고의 원인으로 해킹이 가장 많이 차지한다는 것을 확인할 수 있다.

해킹 피해(개인정보 유출)에 따른 행정처분 사례
얼마전 다음과 같음 메일을 한통 받았다. 보자 마자 "또 털렸군!"하며 한숨이 나왔다.

증말이지...
(혹시나 잊을까봐 그러는지) 잊을만 하면 '니 정보 털렸으니 미안해~'라는 메일이 온다.
원래 사고라는 것이, 아무리 대비한다고 해도 발생하기 마련이라고는 하지만 과연 그런 불가항력적인 요인만 있을까? 서비스 제공자의 보안의식에 문제는 없을까? 과연 수익 대비 보안에 적정한 투자를 하고 있을까? 의아 스럽다.
사실 이 글을 쓰게 된 첫번째 동기도, 이참에 그동안의 굵직한 보안사고에 대한 법적 처분 사례를 확인해 보기 위함이었다. 과연 어떤 처분을 해 왔길래 늘 비슷한 보안 사고가 반복되는지 궁금해서이다.
지금부터 그간 발생한 (해킹 사고로 인한) 개인정보 유출에 대해 행정처분한 사례를 알아보자.
하나투어, 주민등록번호 유출 사고
2017년 9월, 해킹 사고로 인해 49만명의 개인정보가 유출되었고 이 중에서 42만명 가량은 주민등록번호가 포함되어 있었다.
개인적으로는, 2017년 8월 약 한달간 하나투어 구조진단 컨설팅(해당 건과 관련 없는 부문의 컨설팅)을 나갔었는데 바로 다음달에 사고가 터져 기억이 선명하다.
방통위가 발표한 정확한 피해 규모는 다음과 같다. 주민등록번호가 털렸으니 사태가 꽤 심각했다.
[출처: 방송통신위원회]

이 사건은 개인정보보호법이 적용된 사례로, 주관부처인 행정안전부는 개인정보보호법에 근거하여 다음과 같은 행정처분을 내렸다. 참고로 이 사건은 개인정보보호법 제정 이래 처음으로 과징금이 부과된 사례라고 한다.
(과징금 및 과태료)
- 과징금 3억 2,725만원, 과태료 1,800만원 부과
(시정조치 명령)
- 위반행위 즉시 중지
- 대표(CEO) 및 책임있는 임원(CPO 등)의 특별교육 이수
- 개인정보보호 책임자 및 취급자 대상 정기 교육 실시 및 재발방지 대책 수립
- 처분 통지 날로 부터 30일 이내 시정명령 이행결과 제출
(징계 권고)
- 처분 통지 날로부터 2개월 이내에 대표 및 책임있는 임원에 대해 징계할 것을 권고
본 건의 행정처분 사항의 보다 상세한 내용은 다음의 의결 내용을 확인해 보기 바란다.
> (주)하나투어, 개인정보 유출사고로 행정처분 의결
메가스터디, 100만 개인정보 유출사고
2017년 7월, 메가스터디에서는 해킹 사고로 인해 이용자의 아이디, 이름, 생년월일 등 회원정보 123만3,859건(중복제외 111만7227건)의 개인정보가 유출되었다.
방송통신위원회는 정보통신망법에 근거하여 다음과 같이 행정처분을 내렸다.
(과징금 및 과태료)
- 과징금 2억 1,900만원(자신신고로 과징금 추가 감경 10% 적용), 과태료 1,000만원 부과
(시정조치 명령)
- 위반행위 즉시 중지
- 재발 방지대책 수립
- 시정명령 처분사실 공표
자세한 사항은 다음을 확인하기 바란다.
> 2018년 제33차 위원회 결과
여기어때, 숙박정보 및 개인정보 유출 사고
2017년 3월, 숙박앱 '여기어때'는 SQL 인젝션 공격으로 인해 회원들의 숙박 예약 정보와 개인정보가 유출되었다. 서비스 이용자의 숙박예약정보 3,239,210건과 회원정보 178,625건이 유출되었으며 숙박 예약을 한 회원 대상으로 4,817건의 음란문자가 전송되었다.

[출처: 방송통신위원회]
방송통신위원회는 정보통신망법에 근거하여 다음과 같이 행정처분을 내렸다. 참고로 이 사건은 개인정보 유출사고 최초로 책임자 징계를 권고한 사례하고 한다.
(과징금 및 과태료)
- 과징금 3억 100만원, 과태료 2,500만원 부과
(시정조치 명령)
- 위반행위의 중지 및 재발방지대책 수립
- 대표자 및 책임있는 임원에 대한 징계권고, 그 결과를 방통위에 통보
- 시정명령 처분사실 공표
자세한 사항은 다음을 확인하기 바란다.
> 방통위, ㈜위드이노베이션 개인정보 유출사고 엄정 제재
인터파크, 2,500만 개인정보 유출사고
2016년 5월, APT 공격에 의해 인터파크 회원정보가 그야말로 대거 유출되었다.
[출처: 방송통신위원회]

엄청난 규모의 개인정보 유출에 걸맞게 과징금도 역대급으로 높게 책정되었다. 개인정보 유출 사고와 관련해 최대 징수액으로 기록했다. 당시 정보통신망법이 개정(매출액 3%)되어서 법 규정에서의 과징금 상한이 대폭 올라갔기 때문에 가능한 수치였다.
인터파크는 아무리 법 개정이 되었어도 기존의 처분에 비해 너무 과도하다며 형평성 및 비례의 원칙에 어긋난다고 입장을 밝힌바 있다. 인터파크는 행정처분에 불복 소송을 걸었고 1심에서 패소하였다. 이후 재항고를 하여 현재 2심 진행중이라 한다.
(과징금 및 과태료)
- 과징금 44억 8천만원, 과태료 2,500만원 부과
(시정조치 명령)
- 재발방지대책 수립 및 시행
자세한 사항은 다음을 확인하기 바란다.
> 방통위, ㈜인터파크 개인정보 유출사고 엄정 제재
KT, 연속된 개인정보 유출사고
KT는 2012년에 전산망 해킹으로 인해 870만명의 개인정보를 유출한데 이어, 2014년에도 홈페이지가 해킹을 당해 1,170만건의 개인정보가 유출되었다. 2012년 당시 7억 5천만원 가량의 과징금을 처분 받았고 2014년 유출사고에서는 7천만원 과징금 처분을 받았다.
KT는 2004년에도 개인정보 유출사고가 발생한 것을 포함하면 총 3차례나 사고가 반복된 셈이다.
근데 재밌는 것은, 2014년 사건은 과징금 처분 이후 KT가 불복하여 소를 제기했고 결국 법원으로부터 '7천만원 과징금 취소 판결'을 받아 법원이 행정부(방통위)의 처분을 뒤엎은 결과가 나왔다. 현재 2심 진행중이라 한다.
SK 컴즈, 옥션 대규모 개인정보 유출 사고
2008년 옥션에서는 해킹으로 인해 1,863만건의 개인정보가 유출되었다. 2011년에는 SK 컴즈의 네이트,싸이월드가 해킹을 당해 3,500만건의 개인정보가 유출되었다.
두 경우 모두 행정처분은 따로 없었다. 피해를 받은 이용자와 시민단체 등에 의해 손해배상 소송이 진행되었는데, 옥션의 경우 대법원에서 그(옥션)의 손을 들어줘 최종 원고 패소하였다. SK컴즈의 경우 20여건의 소송이 진행되었는데 일부 승소하고 일부 패소했다고 한다.
기타
앞서 사례들을 포함해서 다음과 같이 정리를 해 보았다.

표를 보면, 관련 법이 제정되기 전에는 행정처분 자체가 없었다는 것을 알 수 있다. 그러나 법이 제정되고 갈수록 강화되어 행정처분의 수위도 점점 높아지고 있는 것 같다.
하지만 과연 피해 규모에 대비해서 적정한 처분인가? 하는 생각이 드는 부분도 있다.
논란의 여지가 분명 있을 것이다.
모든 비즈니스 분야에 있어 과도한 규제나 징계는 산업을 위축시켜 발전을 저해시킬 수 있다. 하지만 모든 것이 통신으로 연결되는 초연결 사회로 갈수록 보안 사고는 엄청난 피해를 야기할 것이다.
보안에 대한 경각심을 일깨우고 기업 스스로가 자발적으로 보안에 적절한 투자할 수 있는 제도/사회/문화적 환경 개선이 시급하다는 생각이 든다.
개인적으로는, 잘못을 했을 때 벌을 주는 것도 필요하지만, 잘 했을 대 상을 주는 법안도 나오길 기대한다. 기업이 보안 강화에 사용하는 것이 비용이 아니라 투자가 될 수 있도록 말이다.
'SW개발' 카테고리의 다른 글
| 개인정보의 암호화 대상 및 방법 (0) | 2020.07.28 |
|---|---|
| The Scale Cube (규모 확장성 모델) (0) | 2019.02.21 |
| [웹보안] SQL Injection (1) | 2019.01.28 |
| [웹보안] 브루트 포스(BRUTE FORCE) 공격 (2) | 2019.01.23 |
| [웹보안] 로컬 환경 셋팅과 툴 설치 (1) | 2019.01.17 |
